Say I have a dataset that looks like this:
> dput(df)
structure(list(Fruit = c("Apple", "Apple", "Apple", "Apple",
"Apple", "Apple", "Apple", "Apple", "Apple", "Apple", "Orange",
"Banana", "Banana"), Status = c("Eaten", "Eaten", "Eaten", "Trashed",
"Eaten", "Trashed", "Eaten", "Eaten", "Trashed", "Eaten", "Eaten",
"Trashed", "Trashed")), class = "data.frame", row.names = c(NA,
-13L))
By just looking at it, we see that Apples have the highest count of Trashed, but this is because it also appears most frequently. On the other hand, we see that Banana has 100% occurrences of it being Trashed.
Which function would allow me to see which fruit type is proportionally trashed the most? For example, the output should be: Banana-100% trashed Orange-0% trashed Apple-30% trashed
I would also like to create a visualization for this as well.
Thanks!
CodePudding user response:
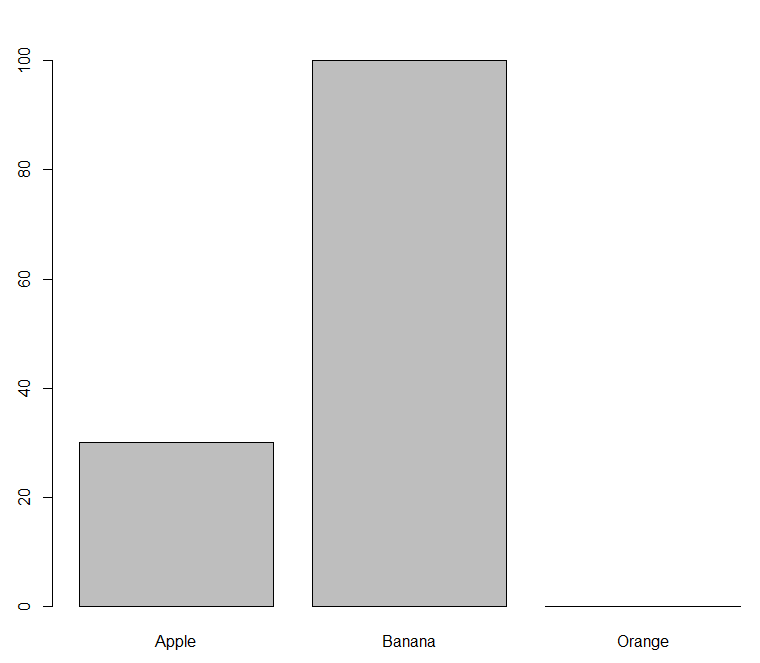
The bare-bones base-r solution is tapply for the calculation, and barplot for the plot:
out <- tapply(df$Status == "Trashed", df$Fruit, mean) * 100
barplot(out)
CodePudding user response:
We could convert the column to logical and do a group by summarise
library(dplyr)
df %>%
group_by(Fruit) %>%
summarise(TrashPerc = 100 * mean(Status == "Trashed"))
-output
# A tibble: 3 × 2
Fruit TrashPerc
<chr> <dbl>
1 Apple 30
2 Banana 100
3 Orange 0
If we need to get bar plot
library(ggplot2)
df %>%
group_by(Fruit) %>%
summarise(TrashPerc = 100 * mean(Status == "Trashed")) %>%
ggplot(aes(x = Fruit, y = TrashPerc))
geom_col()
CodePudding user response:
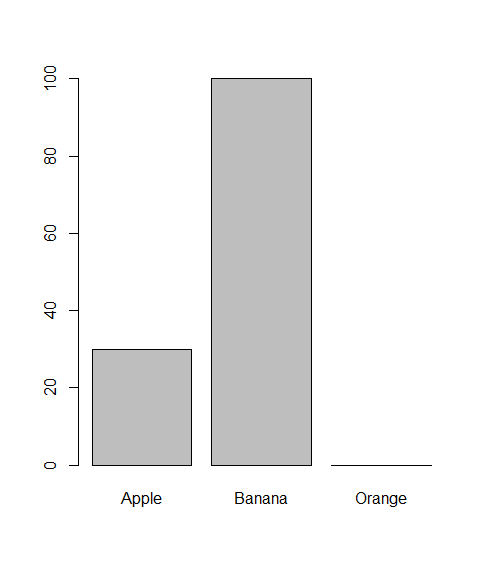
One way to solve your problem using the built-in functions table and proportions to get the relative frequency, and barplot for the plot.
barplot(proportions(table(df), "Fruit")[, "Trashed"] * 100)