import codecademylib3
import pandas as pd
orders = pd.read_csv('shoefly.csv')
print(orders.head())
orders['salutation'] = orders.apply(lambda order: "Dear Mr. " order.last_name if order.gender == 'male' else "Dear Mrs. " order.last_name)
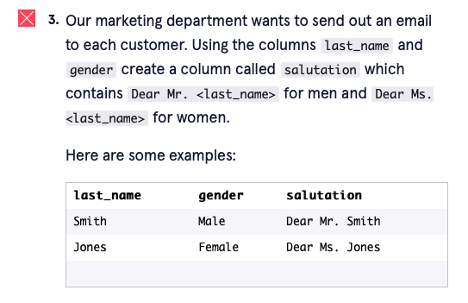
I am getting the following error:
‘Series’ object has no attribute ‘gender’”, ‘occurred at index id’
CodePudding user response:
The default axis for df.apply is 0 (column-wise).
You'll need to apply row-wise, so add axis=1.
orders['salutation'] = orders.apply(
lambda order: "Dear Mr. " order.last_name if order.gender == 'Male' else "Dear Mrs. " order.last_name,
axis=1,
)
or, a touch more shortly using f-strings,
orders['salutation'] = orders.apply(
lambda order: f"Dear {'Mr' if order.gender == 'Male' else 'Mrs'}. {order.last_name}",
axis=1,
)
CodePudding user response:
very simple, just add axis=1
orders['salutation'] = orders.apply(lambda order: "Dear Mr. " order.last_name if order.gender == 'male' else "Dear Mrs. " order.last_name, axis=1)
CodePudding user response:
Instead of the extra expense of using .apply you can use a mask to select male / female rows and do the operation across the entire table. In this example, a Series containing the salutations for just one gender is created on the right, and then .loc is used to apply that series to the like-indexed rows on the left.
import pandas as pd
orders = pd.read_csv('shoefly.csv')
print(orders.head())
is_male = orders['gender'] == 'male'
orders['salutation'] = ''
orders.loc[is_male, 'salutation'] = 'Dear Mr. ' orders[is_male]['last_name']
orders.loc[~is_male, 'salutation'] = 'Dear Mrs. ' orders[~is_male][ 'last_name']
print(orders.head())