Please assist in creating a python function. I have two dataframes, DF1 and DF2. I'd like to add a column to DF1, DF1['Score'], which is based on values contained in DF1 that match the values in DF2.
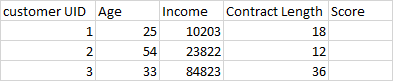
DF1:
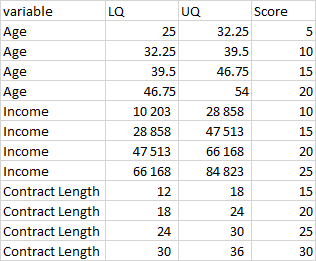
DF2:
import pandas as pd
DF1 = pd.DataFrame({
'Age':[25, 54, 33],
'Income' :[10203, 23822, 84823],
'Contract Length':[18, 12, 36],
#'Score':[]
})
DF2 = pd.DataFrame({
'variable':['Age', 'Age', 'Age', 'Age',
'Income', 'Income', 'Income', 'Income',
'Contract Length', 'Contract Length', 'Contract Length', 'Contract Length'],
'LQ':[ 25, 32.25, 39.5, 46.75, 10203, 28858, 47513, 66168, 12, 18, 24, 30],
'UQ':[ 32.25, 39.5, 46.75, 54, 28858, 47513, 66168, 84823, 18, 24, 30, 36],
'Score':[5, 10, 15, 20, 10, 15, 20, 25, 15, 20, 25, 30]
})
Take customer UID 1 in DF1, since he is 25, with an income of 10,203 and contract length of 18; based on DF2 I want to be able to add a score of 30 to DF1['Score'] for customer 1, calculated as 5 (for age 25 to 32.5) 10 (for income 10,2013 to 28,858) 15 (for contract length of 12 to 18).
Please assist in creating a python function to add the correct scores to DF1['Score'] for all customers.
CodePudding user response:
You can use pandas pandas.DataFrame.apply to iterate through the rows from first dataframe and get the matching condition rows from the second dataframe.
Creating data
dict1 = {'customer UID': {0: 1, 1: 2, 2: 3}, 'Age': {0: 25, 1: 54, 2: 33}, 'Income': {0: 10203, 1: 23822, 2: 84823}, 'Contract Length': {0: 18, 1: 12, 2: 36}, 'Score': {0: '', 1: '', 2: ''}}
dict2 = {'variable': {0: 'Age', 1: 'Age', 2: 'Age', 3: 'Age', 4: 'Income', 5: 'Income', 6: 'Income', 7: 'Income', 8: 'Contract Length', 9: 'Contract Length', 10: 'Contract Length', 11: 'Contract Length'}, 'LQ': {0: 25.0, 1: 32.25, 2: 39.5, 3: 46.75, 4: 10203.0, 5: 28858.0, 6: 17513.0, 7: 66168.0, 8: 12.0, 9: 18.0, 10: 24.0, 11: 30.0}, 'UQ': {0: 32.25, 1: 39.5, 2: 46.75, 3: 54.0, 4: 28858.0, 5: 47513.0, 6: 66168.0, 7: 84823.0, 8: 18.0, 9: 24.0, 10: 30.0, 11: 36.0}, 'Score': {0: 5, 1: 10, 2: 15, 3: 20, 4: 10, 5: 15, 6: 20, 7: 25, 8: 15, 9: 20, 10: 25, 11: 30}}
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
Generating output
def get_values(row):
age_condition = (row.Age >= df2['LQ']) & (row.Age <= df2['UQ']) & (df2.variable == 'Age')
income_condition = (row.Income >= df2['LQ']) & (row.Income <= df2['UQ']) & (df2.variable == 'Income')
contract_condition = (row['Contract Length'] >= df2['LQ']) & (row['Contract Length'] <= df2['UQ']) & (df2.variable == 'Contract Length')
return df2[age_condition].Score.values[0] df2[income_condition].Score.values[0] df2[contract_condition].Score.values[0]
df1['Score'] = df1.apply(get_values, axis=1)
Output :
This gives us :
df1
customer UID Age Income Contract Length Score
0 1 25 10203 18 30
1 2 54 23822 12 45
2 3 33 84823 36 65
CodePudding user response:
For efficiency, you need to use a merge_asof after performing a melt on DF1:
DF1['Score'] = (pd
.merge_asof(DF1.astype(float).reset_index().melt('index').sort_values(by='value'),
DF2.sort_values(by='UQ'),
by='variable', left_on='value', right_on='UQ', direction='forward'
)
.groupby('index')['Score'].sum()
)
output:
Age Income Contract Length Score
0 25 10203 18 30.0
1 54 23822 12 45.0
2 33 84823 36 65.0
intermediates:
# reshape DF1 to long form
DF1.astype(float).reset_index().melt('index').sort_values(by='value')
index variable value
7 1 Contract Length 12.0
6 0 Contract Length 18.0
0 0 Age 25.0
2 2 Age 33.0
8 2 Contract Length 36.0
1 1 Age 54.0
3 0 Income 10203.0
4 1 Income 23822.0
5 2 Income 84823.0
# merge asof with DF2 (i.e. find the closest UQ value greater that the target
(pd
.merge_asof(DF1.astype(float).reset_index().melt('index').sort_values(by='value'),
DF2.sort_values(by='UQ'),
by='variable', left_on='value', right_on='UQ', direction='forward'
)
)
index variable value LQ UQ Score
0 1 Contract Length 12.0 12.00 18.00 15
1 0 Contract Length 18.0 12.00 18.00 15
2 0 Age 25.0 25.00 32.25 5
3 2 Age 33.0 32.25 39.50 10
4 2 Contract Length 36.0 30.00 36.00 30
5 1 Age 54.0 46.75 54.00 20
6 0 Income 10203.0 10203.00 28858.00 10
7 1 Income 23822.0 10203.00 28858.00 10
8 2 Income 84823.0 66168.00 84823.00 25
# finally, group by "index" and sum the Score