I'm working with SQL Server.
I need to join two tables based on the "Ctrl" column. The first table, "Cad_Clients", contains client information, while the second one, "Cad_Colors", has descriptions of the information. The condition for joining them is that the value of "Ctrl" must be the same in both tables. However, the distribution needs to be exact, meaning that duplicates cannot occur.
Imagine that I create a 'for' loop in the 'Cad_Colors' table. In each iteration, I add a record from the table to 'Cad_Clients' as long as the 'Ctrl' value matches. Afterward, I delete that record from 'Cad_Colors'. If the looped table becomes empty or the loop reaches its end, it means that I have distributed as many records as possible. That's all, but I don't want to use a loop in the database; I'm confident that by discussing it here, we can achieve a much more concise result.
Visual depiction of the issue:
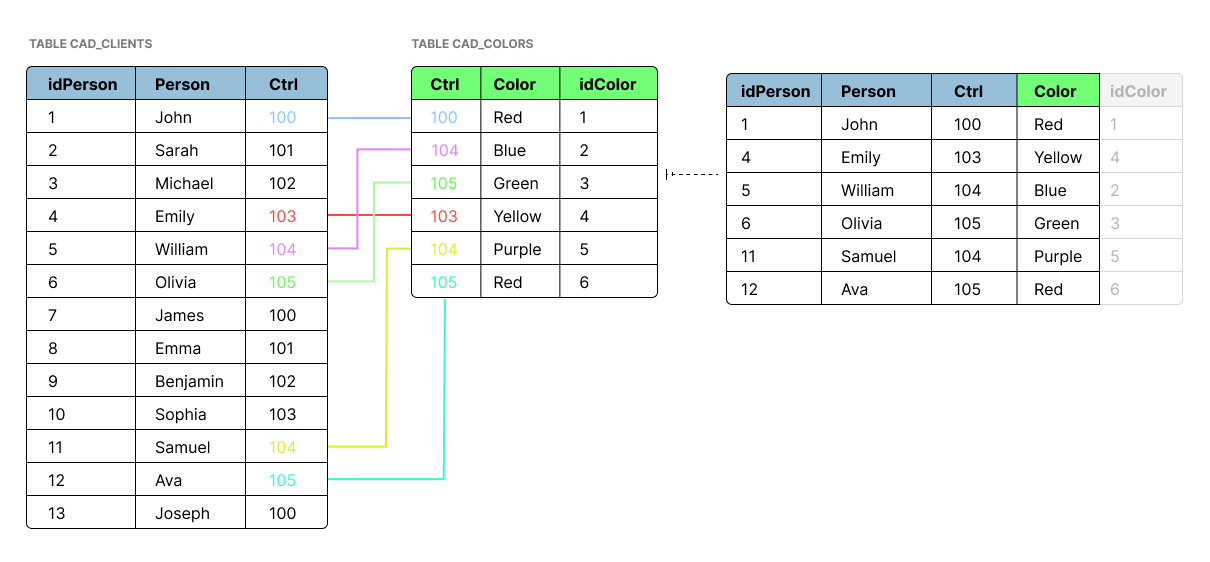
Cad_Clients
| idPerson | Person | Ctrl |
|----------|----------------|-------|
| 1 | John | 100 |
| 2 | Sarah | 101 |
| 3 | Michael | 102 |
| 4 | Emily | 103 |
| 5 | William | 104 |
| 6 | Olivia | 105 |
| 7 | James | 100 |
| 8 | Emma | 101 |
| 9 | Benjamin | 102 |
| 10 | Sophia | 103 |
| 11 | Samuel | 104 |
| 12 | Ava | 105 |
| 13 | Joseph | 100 |
Cad_Colors
| Ctrl | Color | idColor |
|------|----------|---------|
| 100 | Red | 1 |
| 104 | Blue | 2 |
| 105 | Green | 3 |
| 103 | Yellow | 4 |
| 104 | Purple | 5 |
| 105 | Red | 6 |
Combining both tables:
| idPerson | Person | Ctrl | Color |
|----------|---------|------|--------|
| 1 | John | 100 | Red |
| 4 | Emily | 103 | Yellow |
| 5 | William | 104 | Blue |
| 6 | Olivia | 105 | Green |
| 11 | Samuel | 104 | Purple |
| 12 | Ava | 105 | Red |
Some unsuccessful attempts:
INSERT INTO @Tmp
SELECT ccl.idPerson, ccl.Person, ccl.Ctrl,
(SELECT TOP 1 cco.idColor FROM Cad_Colors cco WHERE cco.Ctrl = ccl.Ctrl AND cco.idColor NOT IN(SELECT idColor FROM @Tmp))
FROM Cad_Clients ccl
INSERT INTO @Tmp
SELECT ccl.idPerson, ccl.Person, ccl.Ctrl, cco.idColor, cco.Color
FROM Cad_Clients ccl
JOIN (SELECT TOP 1 cco.* FROM Cad_Colors cco WHERE cco.idColor NOT IN(SELECT idColor FROM @Tmp)) cco ON cco.Ctrl = ccl.Ctrl
INSERT INTO @Tmp
SELECT ccl.idPerson, ccl.Person, ccl.Ctrl, cco.idColor, cco.Color
FROM Cad_Clients ccl
JOIN Cad_Colors cco ON cco.Ctrl = ccl.Ctrl
WHERE NOT EXISTS (SELECT 1 FROM @Tmp WHERE Ctrl = cco.Ctrl)
MERGE INTO Cad_Clients AS target
USING Cad_Colors AS source
ON target.Ctrl = source.Ctrl
WHEN MATCHED THEN
UPDATE SET target.idPerson = target.idPerson
OUTPUT inserted.idPerson, inserted.Person, inserted.Ctrl, inserted.idColor, inserted.Color INTO @tmp;
Assistance in creating the scenarios:
CREATE TABLE Cad_Clients( [idPerson] [int] IDENTITY(1,1) NOT NULL, [Person] [varchar](60) NULL, [Ctrl] [int] NULL );
CREATE TABLE Cad_Colors( [Ctrl] [int] NULL, [Color] [varchar](60) NULL, [idColor] [int] IDENTITY(1,1) NOT NULL );
INSERT INTO Cad_Clients (Person, Ctrl) VALUES ('John',100), ('Sarah',101), ('Michael',102), ('Emily',103), ('William',104), ('Olivia',105), ('James',100), ('Emma',101), ('Benjamin',102), ('Sophia',103), ('Samuel',104), ('Ava',105), ('Joseph',100);
INSERT INTO Cad_Colors (Ctrl, Color) VALUES (100, 'Red'), (104, 'Blue'), (105, 'Green'), (103, 'Yellow'), (104, 'Purple'), (105, 'Red');
DECLARE @Tmp TABLE( idPerson INT, Person VARCHAR(60), Ctrl INT, idColor INT /*Color VARCHAR(60)*/ );
CodePudding user response:
This should be a simple ROW_NUMBER join:
WITH persons AS (
SELECT *
FROM (
VALUES (1, N'John', 100)
, (2, N'Sarah', 101)
, (3, N'Michael', 102)
, (4, N'Emily', 103)
, (5, N'William', 104)
, (6, N'Olivia', 105)
, (7, N'James', 100)
, (8, N'Emma', 101)
, (9, N'Benjamin', 102)
, (10, N'Sophia', 103)
, (11, N'Samuel', 104)
, (12, N'Ava', 105)
, (13, N'Joseph', 100)
) t (idPerson,Person,Ctrl)
)
, colors AS (
SELECT *
FROM
(
VALUES (100, N'Red', 1)
, (104, N'Blue', 2)
, (105, N'Green', 3)
, (103, N'Yellow', 4)
, (104, N'Purple', 5)
, (105, N'Red', 6)
) t (Ctrl,Color,idColor)
)
SELECT p.idPerson, p.Person, p.Ctrl, c.Color
FROM (
SELECT *
, ROW_NUMBER() OVER(partition BY ctrl ORDER BY idperson) AS sort
FROM persons c
) p
INNER JOIN (
SELECT *
, ROW_NUMBER() OVER(partition BY ctrl ORDER BY idcolor) AS sort
FROM colors
) c
ON c.Ctrl = p.Ctrl
AND c.sort = p.sort
You create a counter for every person grouped by Ctrl like ROW_NUMBER() OVER(partition BY ctrl ORDER BY idperson) and do the same for the Colors, and then join on them together.
Output:
| idPerson | Person | Ctrl | Color |
|---|---|---|---|
| 1 | John | 100 | Red |
| 4 | Emily | 103 | Yellow |
| 5 | William | 104 | Blue |
| 11 | Samuel | 104 | Purple |
| 6 | Olivia | 105 | Green |
| 12 | Ava | 105 | Red |
CodePudding user response:
Here is the solution. You can make use of row_number window function to achieve this.
select
a.idPerson ,
a.Person ,
a.Ctrl ,
b.Color
from
(select * , row_number () over(partition by Ctrl order by idPerson) as cad_person_seq from Cad_Clients)
as a inner join
(select * , row_number () over(partition by Ctrl order by idColor) as cad_color_seq from Cad_Colors) as b
on a.Ctrl = b.Ctrl and a.cad_person_seq = b.cad_color_seq
order by a.cad_person_seq , a.Ctrl;