Nanolog in two aspects of low latency and high throughput do some subtle improvement, well worth the low latency technology in-depth study, interested friends
01 丨 Nanolog how fast
C + + Log system there are many open source projects, such as log4clpus, glog, spdlog, boostlog, log4j, etc., relative to the common Log database, one or two orders of magnitude faster Nanalog,
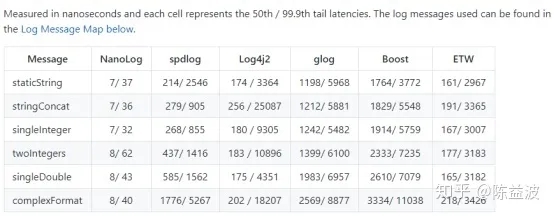
As shown in the above, Nanolog call overhead median single-digit nanoseconds, several other well-known open source log call requires hundreds or even thousands of nanoseconds, median Nanolog and 99.9 a small delay than the other one to two orders of magnitude,
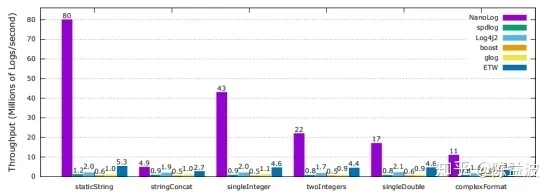
Above for different logging library print contrast throughput, purple for Nanolog, is higher than other logging system throughput per second several times to dozens times ,

Above, I run the Benchmark test result, can output 143494928 per second log, an average of 7 ns, the output of a written log average delay only 2 ns each , and I also tested the output string plus orthopedic and floating like a log, found that the delay is only 5 ns each ,
02 丨 Nanolog fast why
Used first in order to reduce the delay, Nanolog first programming technology is unlocked programming , says unlocked programming here is really no lock, rather than some articles written lock based on CAS programming called lock-free programming, in a world of low latency, CAS lock and lock, unlocked programming makes any writer threads can very fast to finish in a deterministic time calls, not stuck because of the different thread competition resources uncertain time,
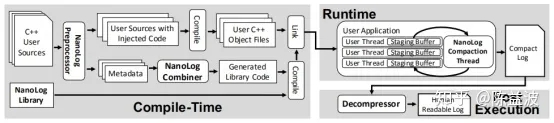
Based on c + + 11 standard introduced in keyword __thread, Nanolog for each thread creates an independent unlocked circular queue, memory block is the basis of multithreading can synchronization, based on the memory block can realize lock-free queue, single producer and the consumer can use a lock-free queue to implement unlocked programming, the programming is unlocked a foundation, through multiple lock-free queue can be done more producers single consumers unlocked programming, which is with low latency programming skills,
降低延迟的第二个关键点便是尽量减少cache miss,低延迟系统要应对的头号敌人就是cache miss,低延迟系统要尽量避免cache miss,为了减少队列生产者和消费者多线程造成队列头尾指针判断时的cache miss,生产者端会缓存消费者线程在环形队列中的尾的位置,只有当空间不足时才重新读取一次队尾位置,这样就不会每次写入都可能发生cache miss,而是只有写满一次环形队列时,才会发生一次cache miss,编写多线程低延迟系统时要合理规划结构体的内存布局,按线程对变量的读写情况规划变量定义顺序,尽可能按线程访问顺序定义结构体顺序,同一线程的放一起,不同线程间会改变的变量中间加一个cache line长度的空间进行分开,避免因false sharing导致cache miss,比如该项目中的环形队列中作者便放了两条cache line长度的定义进行隔离(参考RuntimeLogger.h中的charcacheLineSpacer[2*Util::BYTES_PER_CACHE_LINE]),这里为什么不是一倍而是两倍长度,本人也有点费解,有谁了解的希望能指点一二,
third, when talking about a nanosecond level delay, as far as possible to avoid any slow function calls for , through the system interface to get time is slow, the Nanolog USES is recorded, the value of TSC register system to record the time , then this value reduction in the log processing threads into calendar time, this method makes the log write threads access delay to reduce time to read the register level, is also a low-latency trading system will use the skills, low latency system should as far as possible avoid using slow interface call, such as gettimeofday for low delay system is slow calls, to avoid to use in the core thread,
convert variable to the string format conversion is a very time-consuming operation, vice thread execution Nanolog put formatting , if you want to achieve low latency, system just as much as possible to avoid formatting in the core thread processing, such as the value into a string, can avoid shall be avoided, all on the auxiliary thread processing,
fourth is worth learning, in some time the biggest part can pass the information compression and decompression to speed , for logging system, write file is a bottleneck, but given that most of the time log does not need to live to see, can write first compressed format of the log file to reduce the amount of writing, when to see the log formats you can read and extract the adult eye, at the same time a large number of repeat static string log information is the same, there is no need to call every time to write the same static string, only need to record a or precompiled, Nanolog offers two versions of a precompiled version is disposed of in the precompiled runtime will not overwrite a static string, only write variable information, such as plastic, floating-point string variable , and the compact operation only when the log write compressed binary information in order to improve the I/o throughput, upon the completion of the log, by subsequent decompression to restore the adult eye to read a text file, this idea is well worth learning, such as network transmission, the long-distance exchange of signal transmission across the network, the considering the CPU speed is usually much faster than the shuttle network transmission speed, can do to data compression, decompression to use after you receive the
03 丨 Nanolog source code and papers
Nanolog 17 standards development, based on the c + + source code address below: https://github.com/PlatformLab/NanoLog
On the note, making a standard development based on c + + 11 open source projects of the same name, don't make a mistake, the c + + 11 project tested delay than the corresponding results are really about 100 times slower,
paper USENIX annual technical conference in 2018, the download address:
https://www.usenix.org/conference/atc18/presentation/yang-stephen
04 丨 improve
finally provides a without a compressed version of the code for reference , Nanolog compression feature makes for tail -f can real-time log becomes not so convenient, given that some scenes for call low latency, not the pursuit of high throughput, every time to check the log need to unzip it is not convenient to use, for this, we can modify the code, and compression of the auxiliary thread storage this step to output the result of the human eye can be read directly, such changes won't increase the delay call, just can reduce throughput, for not paying attention to the throughput to focus solely on the application of the low latency can change the direct output version of reference Zhu Daniu, making links: zwzw1/Nanolog