I'm trying to scrape facebook pages for analytical purposes using selenium.
http://www.facebook.com/123439757700947
Viewing page source I found the tag I need:
<title>Tzipi Hotovely - ציפי חוטובלי</title>
I used the method:
politician_name = driver.find_element_by_tag_name('title')
politician_name.text
which returned:
''
I would also like to get the number of people who liked the page from the following dictionary item:
"page_likers":{"global_likers_count":92987}
which is under the <script> tag:
I would love for some help...
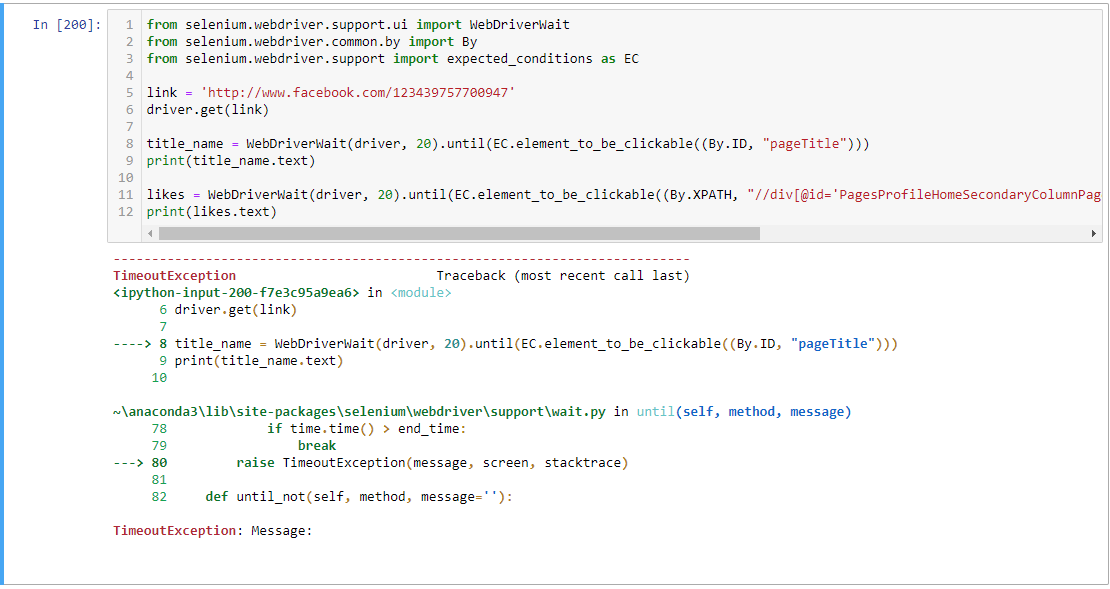
I was trying the solution proposed:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
link = 'http://www.facebook.com/123439757700947'
driver.get(link)
title_name = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.ID, "pageTitle")))
print(title_name.text)
likes = WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//div[@id='PagesProfileHomeSecondaryColumnPagelet']//descendant::div[contains(@class,'clearfix')]/div[2]/div")))
print(likes.text)
got TimeoutException
CodePudding user response:
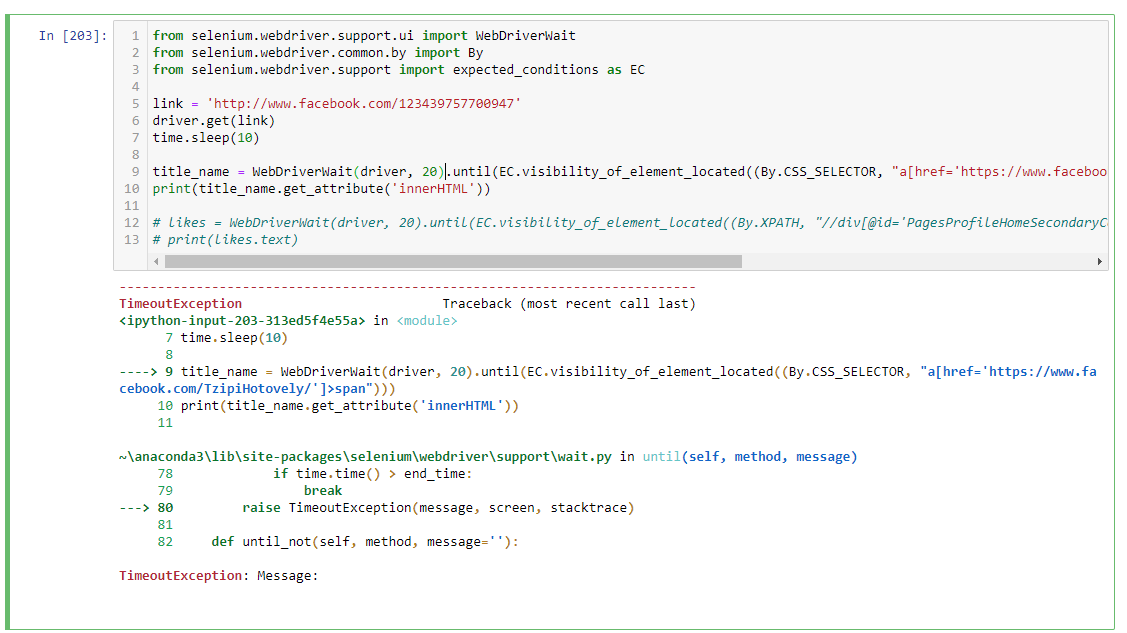
You have to induce explicit waits.
I see this id pageTitle is unique in HTMLDOM.
link = 'http://www.facebook.com/123439757700947'
driver.get(link)
title_name = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "a[href='https://www.facebook.com/TzipiHotovely/']>span")))
print(title_name.get_attribute('innerHTML'))
likes = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[@id='PagesProfileHomeSecondaryColumnPagelet']//descendant::div[contains(@class,'clearfix')]/div[2]/div")))
print(likes.text)
Imports:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
CodePudding user response:
Ok, this code covered most cases
only 14 out of 76 page_ids returned blank
politicains_dict = {}
BASE_LINK = 'http://www.facebook.com/'
# time.sleep(5)
for id in page_ids_list:
link = BASE_LINK str(id) '/'
driver.get(link)
time.sleep(10)
try:
politician_name = driver.find_element_by_xpath("/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div[1]/div[2]/div/div/div/div[2]/div/div/div[1]/h2/span/span")
likes = driver.find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div[4]/div[2]/div/div[1]/div[2]/div[2]/div/div/div/div[2]/div[3]/div[1]/div/div/div[2]/div/div/span/span[1]')
followers = driver.find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div[4]/div[2]/div/div[1]/div[2]/div[2]/div/div/div/div[2]/div[4]/div/div/div/div[2]/div/div/span/span')
politicains_dict[id] = [politician_name.text, likes.text, followers.text]
except:
try:
politician_name = driver.find_element_by_xpath("/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div/div/div[1]/div[2]/div/div/div[2]/div/div/div/div[1]/div/div/span/h1")
followers = driver.find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div/div/div[4]/div[2]/div/div[1]/div[2]/div/div[1]/div/div/div/div/div[2]/div/div/ul/div[1]/div[2]/div/div/span/a')
politicains_dict[id] = [politician_name.text, '', followers.text]
except:
try:
politician_name = driver.find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div[1]/div[2]/div/div/div/div[2]/div/div/div[1]/h2/span/span')
likes = driver.find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div[4]/div[2]/div/div[1]/div[2]/div[1]/div/div/div/div[2]/div[3]/div[1]/div/div/div[2]/div/div/span/span[1]')
followers = driver.find_element_by_xpath('/html/body/div[1]/div/div[1]/div/div[3]/div/div/div[1]/div[1]/div[4]/div[2]/div/div[1]/div[2]/div[1]/div/div/div/div[2]/div[4]/div/div/div/div[2]/div/div/span/span')
politicains_dict[id] = [politician_name.text, likes.text, followers.text]
except:
politicains_dict[id] = ["", "", ""]
continue
CodePudding user response:
Try below xpath to extract title. It might work.
//div[contains(@aria-label,'Send Message')]//parent::div//parent::div//parent::div//parent::div//parent::div//h2/span/span