So I have a data frame
testdf = pd.DataFrame({"loc" : ["ab12","bc12","cd12","ab12","bc13","cd12"], "months" :
["Jun21","Jun21","July21","July21","Aug21","Aug21"], "dept" :
["dep1","dep2","dep3","dep2","dep1","dep3"], "count": [15, 16, 15, 92, 90, 2]})
That looks like this:
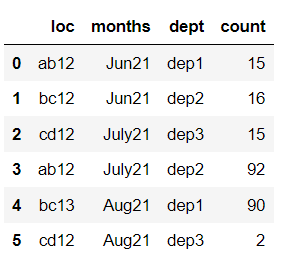
When I pivot it,
df = pd.pivot_table(testdf, values = ['count'], index = ['loc','dept'], columns = ['months'], aggfunc=np.sum).reset_index()
df.columns = df.columns.droplevel(0)
df
it looks like this:
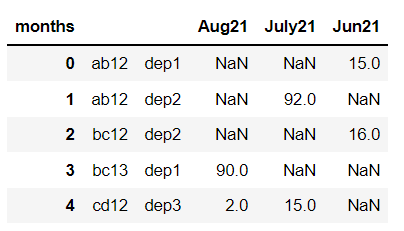
I am looking for a sort function which will sort only the months columns in sequence and not the first 2 columns i.e loc & dept.
when I try this:
df.sort_values(by = ['Jun21'],ascending = False, inplace = True, axis = 1, ignore_index=True)[2:]
it gives me error.
I want the columns to be in sequence Jun21, Jul21, Aug21
I am looking for something which will make it dynamic and I wont need to manually change the sequence when the month changes.
Any hint will be really appreciated.
CodePudding user response:
We can start by converting the column months in datetime like so :
>>> testdf.months = (pd.to_datetime(testdf.months, format="%b%y", errors='coerce'))
>>> testdf
loc months dept count
0 ab12 2021-06-01 dep1 15
1 bc12 2021-06-01 dep2 16
2 cd12 2021-07-01 dep3 15
3 ab12 2021-07-01 dep2 92
4 bc13 2021-08-01 dep1 90
5 cd12 2021-08-01 dep3 2
Then, we apply your code to get the pivot :
>>> df = pd.pivot_table(testdf, values = ['count'], index = ['loc','dept'], columns = ['months'], aggfunc=np.sum).reset_index()
>>> df.columns = df.columns.droplevel(0)
>>> df
months NaT NaT 2021-06-01 2021-07-01 2021-08-01
0 ab12 dep1 15.0 NaN NaN
1 ab12 dep2 NaN 92.0 NaN
2 bc12 dep2 16.0 NaN NaN
3 bc13 dep1 NaN NaN 90.0
4 cd12 dep3 NaN 15.0 2.0
And to finish we can reformat the column names using strftime to get the expected result :
>>> df.columns = df.columns.map(lambda t: t.strftime('%b%y') if pd.notnull(t) else '')
>>> df
months Jun21 Jul21 Aug21
0 ab12 dep1 15.0 NaN NaN
1 ab12 dep2 NaN 92.0 NaN
2 bc12 dep2 16.0 NaN NaN
3 bc13 dep1 NaN NaN 90.0
4 cd12 dep3 NaN 15.0 2.0
CodePudding user response:
It is quite simple if you do using groupby
df = testdf.groupby(['loc', 'dept', 'months']).sum().unstack(level=2)
df = df.reindex(['Jun21', 'July21', 'Aug21'], axis=1, level=1)
Output
count
months Jun21 July21 Aug21
loc dept
ab12 dep1 15.0 NaN NaN
dep2 NaN 92.0 NaN
bc12 dep2 16.0 NaN NaN
bc13 dep1 NaN NaN 90.0
cd12 dep3 NaN 15.0 2.0