Require to only use regex for scrapping the rating links, and total is 250 rating links then save it to txt file.
website: 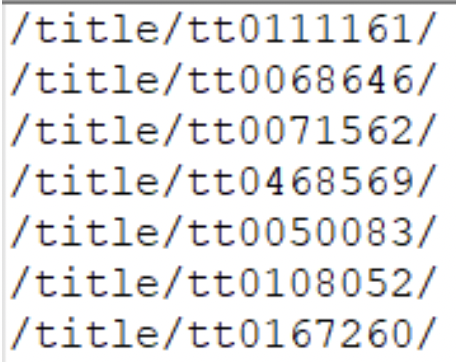 At the end should look something like this
At the end should look something like this
I have tried previously using beautifulsoup4 but then it was required to only use regular expressions to extract, so I am not sure about it. Do I use re.findall to look for all the links?
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = 'https://www.imdb.com/chart/top'
html = urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
count = 0
all_urls = list()
for tdtag in soup.find_all(class_ = "titleColumn"):
url = tdtag.a['href']
all_urls.append(url)
count = 1
print('total of {} urls'.format(count))
data = np.array(all_urls)
print(data)
np.savetxt('urls.txt', data, fmt = '%s', encoding = 'utf-8')
CodePudding user response:
Here's my clumsy attempt at that:
from re import compile
from requests import get
BASE = 'https://www.imdb.com/chart/top'
page = get(BASE)
pattern = compile(r'<a href="/title/([a-z0-9] )/')
URLs = pattern.findall(page.text)
try:
f = open('urls.txt', 'x', encoding='utf-8')
except FileExistsError as e:
print(e)
else:
for i in set(URLs):
f.write(f'/title/{i}/\n')
f.close()
requests.get(URL)is a response object. So, you needrequests.get(URL).textfor regex to work on ithttps://regex101.com/ is a handy website you can use to build and test regex
try,except,elsecan be used to handle errors if anurl.txtfile already existsf-strings are super convenient and I highly recommend you to learn and use them
CodePudding user response:
Use re.findall:
Replace:
all_urls = list()
for tdtag in soup.find_all(class_ = "titleColumn"):
url = tdtag.a['href']
all_urls.append(url)
count = 1
By:
import re
text = html.read().decode('utf-8')
all_urls = list(set(re.findall(r'/title/tt\d ', text)))
count = len(all_urls)