I am trying to write a multi-index data frame to excel using pandas styling and I am getting an error.
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randn(9,4), pd.MultiIndex.from_product([['A', 'B','C'], ['r1', 'r2','r3']]), columns=[['E1','E1','E2','E2'],['d1','d2','d1','d2']])
def highlight_max(s, props=''):
return np.where(s == np.nanmax(s.values), props, '')
def highlight_all_by_condition (value, condition, props=''):
return np.where(value >= condition, props, '')
def highlight_max_value_by_condition(value, condition, props=''):
return np.where(np.nanmax(value) >= condition, props, '')
df_formatted = df.style.set_properties(**{'font-family': 'Arial','font-size': '10pt'})
unique_column_list = list(set(df.columns.get_level_values(0)))
idx = pd.IndexSlice
for each in unique_column_list:
slice_=idx[idx[each]]
df_formatted = df_formatted.apply(highlight_max, props='color:black; font-weight: bold', axis=1, subset=slice_)\
.apply(highlight_all_by_condition, condition = 0.55, props='color:red;font-weight: bold; background-color: #ffe6e6', axis=1, subset=slice_)\
.apply(highlight_max_value_by_condition, condition = 1, props='color:green;font-weight: bold; background-color: #ffff33', axis=1, subset=slice_)
df_formatted.to_excel("test.xlsx", engine = 'openpyxl')
I am getting the following error:
ValueError: Function <function highlight_max_value_by_condition at 0x000001EE1394E940> returned the wrong shape.
Result has shape: (9,)
Expected shape: (9, 2)
The second styling function (highlight_max_value_by_condition) is a conditional styling, where it needs to highlight the max value only if it satisfies the condition and if I remove that styling function, then I don't get any error.
Any help is much appreciated. Thanks in advance.
CodePudding user response:
Assuming we're looking for highlight_max_value_by_condition is meant to apply styles to cells which are both the max in the subset and fulfill the condition we can add an & to combine the conditions:
def highlight_max_value_by_condition(value, condition, props=''):
return np.where(
(value == np.nanmax(value)) & (value >= condition),
props,
''
)
Beyond that, however, there are quite a few things we can do to cleanup the general approach.
Styler objects compound naturally, there is no need to assign back. In addition instead of using list(set( to get the level values, 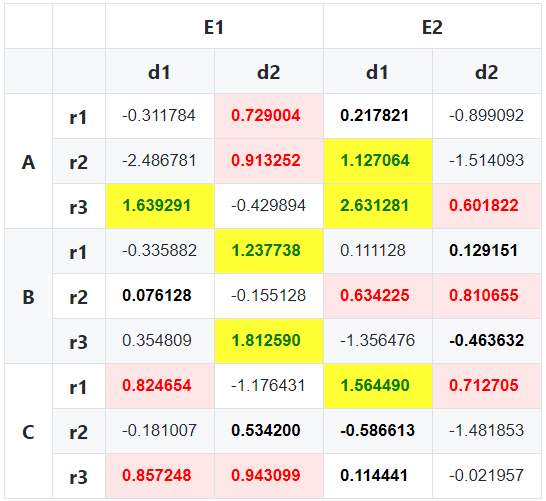
Setup made reproducible with seed(6) and with modified function
import numpy as np
import pandas as pd
np.random.seed(6)
df = pd.DataFrame(
np.random.randn(9, 4),
pd.MultiIndex.from_product([['A', 'B', 'C'], ['r1', 'r2', 'r3']]),
columns=[['E1', 'E1', 'E2', 'E2'], ['d1', 'd2', 'd1', 'd2']]
)
def highlight_max(s, props=''):
return np.where(s == np.nanmax(s.values), props, '')
def highlight_all_by_condition(value, condition, props=''):
return np.where(value >= condition, props, '')
def highlight_max_value_by_condition(value, condition, props=''):
return np.where(
(value == np.nanmax(value)) & (value >= condition),
props,
''
)
df:
E1 E2
d1 d2 d1 d2
A r1 -0.311784 0.729004 0.217821 -0.899092
r2 -2.486781 0.913252 1.127064 -1.514093
r3 1.639291 -0.429894 2.631281 0.601822
B r1 -0.335882 1.237738 0.111128 0.129151
r2 0.076128 -0.155128 0.634225 0.810655
r3 0.354809 1.812590 -1.356476 -0.463632
C r1 0.824654 -1.176431 1.564490 0.712705
r2 -0.181007 0.534200 -0.586613 -1.481853
r3 0.857248 0.943099 0.114441 -0.021957