So, basically, I have a DataFrame looking like this:
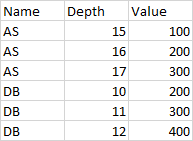
and the task is to make increment of 'Depth' with 0.1 step (add new rows), also interpolate the 'Value's accordingly.
It should look like this: (bottom part cropped because of size)
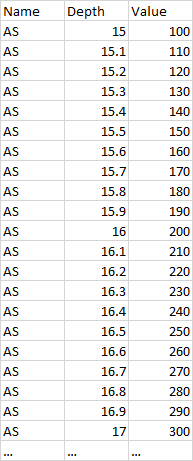
Here is the draft of code I wrote:
import pandas as pd
df = pd.DataFrame({'Name': ['AS', 'AS', 'AS', 'DB', 'DB', 'DB'],
'Depth': [15, 16, 17, 10, 11, 12],
'Value': [100, 200, 300, 200, 300, 400]})
df['Depth']= ... #make it here with increment 0.1
df['Value'] = df['Value'].interpolate(method=linear)
df['Name'] = ... #copy it for each empty row
df.to_csv('Interpolated values.csv')
CodePudding user response:
Here's a solution which will allow you to interpolate values with any variation of stepsize (assuming steps fall neatly between integers) and more flexibility with interpolation:
my_df_list = []
step = 0.1
for label, group in df.sort_values('Depth').groupby('Name'):
# Create a lookup dictionary for interpolation lookup
lookup_dict = {x[0]:x[1] for x in group[['Depth', 'Value']].values}
# Use np.linespace because of the strictness of start and end values
new_index = np.linspace(
start = group['Depth'].min(),
stop = group['Depth'].max(),
num = int(1/step) * np.ptp(group['Depth']) 1
)
new_values = pd.Series(
lookup_dict.get(round(x, 1)) for x in new_index
).interpolate()
# Create a tmp df with your values
df_tmp = pd.DataFrame.from_dict({
'Name': [label] * len(new_index),
'Depth': new_index,
'Value':new_values
})
my_df_list.append(df_tmp)
# Finally, combine all dfs
df_final = pd.concat(my_df_list, ignore_index=True)
Name Depth Value
0 AS 15.0 100.0
1 AS 15.1 110.0
...
19 AS 16.9 290.0
20 AS 17.0 300.0
21 DB 10.0 200.0
22 DB 10.1 210.0
...
39 DB 11.8 380.0
40 DB 11.9 390.0
41 DB 12.0 400.0
CodePudding user response:
Part 1:
I choose not to use iteration, assign new values to the whole column instead.
import pandas as pd
import numpy as np
df = pd.DataFrame({'Name': ['AS', 'AS', 'AS', 'DB', 'DB', 'DB'],
'Depth': [15, 16, 17, 10, 11, 12],
'Value':[100, 200, 300, 200, 300, 400]
})
Output:
Name Depth Value
0 AS 15 100
1 AS 16 200
2 AS 17 300
3 DB 10 200
4 DB 11 300
5 DB 12 400
use
lento get the length of the column.df[column][0]to get the initial value. If you do have a specific initial value then just skip this step. Assign your initial value to it.
ini_1 = df['Depth'][0] # initial value
ini_2 = df['Value'][0] # initial value
length = len(df)
step_1 = 0.1
step_2 = 10
df['Depth'] = np.arange(ini_1, ini_1 length*step_1, step_1)
df['Value'] = np.arange(ini_2, ini_2 length*step_2, step_2)
output
Name Depth Value
0 AS 15.0 100
1 AS 15.1 110
2 AS 15.2 120
3 DB 15.3 130
4 DB 15.4 140
5 DB 15.5 150
Since we don't know the variant regulation between Name and Depth, but it's another aspect that avoids iterate into every single row.
Part 2:
Suppose every name-depth group expands to 10 items
and follow the increment of 0.1 and 10 on Depth and Value respectively.
Here's the step:
- load the dataframe
import pandas as pd
import numpy as np
df = pd.DataFrame({'Name': ['AS', 'AS', 'AS', 'DB', 'DB', 'DB'],
'Depth': [15, 16, 17, 10, 11, 12],
'Value':[100, 200, 300, 200, 300, 400]
})
- expand
dfto 10X:
dfn = pd.concat([df]*10,ignore_index=False).sort_index()
- It's an arithmetic progression:
forDeptha = 0, d = 0.1, length = 10
forValuea = 0, d = 10, length = 10
Taking them as vector(1D array) summation in eachName-Depthgroup:
a = 0
d_depth = 0.1
d_value = 10
length = 10
arithmetric_1 = [round(a d_depth * (n - 1),2) for n in range(1, length 1)] # arithmetic progression series for Depth
arithmetric_2 = [round(a d_value * (n - 1),2) for n in range(1, length 1)] # arithmetic progression series for Value
- the main part
for i in set(dfn.index):
dfn.loc[i,'Depth'] = dfn.loc[i,'Depth'].array arithmetric_1
dfn.loc[i,'Value'] = dfn.loc[i,'Value'].array arithmetric_2
summary:
now you get dataframe dfn as the result base on the assumption. This manipulation try to decrease the loop-times, and use vector aspect to deal with the problem(if you have huge datasets).
Name Depth Value
0 AS 15.0 100
0 AS 15.1 110
0 AS 15.2 120
0 AS 15.3 130
0 AS 15.4 140
0 AS 15.5 150
0 AS 15.6 160
0 AS 15.7 170
0 AS 15.8 180
0 AS 15.9 190
1 AS 16.0 200
1 AS 16.1 210
1 AS 16.2 220
1 AS 16.3 230
1 AS 16.4 240
1 AS 16.5 250
1 AS 16.6 260
1 AS 16.7 270
1 AS 16.8 280
1 AS 16.9 290
2 AS 17.0 300
2 AS 17.1 310
:
:
CodePudding user response:
The following given solution will solve the problem.
import pandas as pd
df = pd.DataFrame({'Name': ['AS', 'AS', 'AS', 'DB', 'DB', 'DB'],
'Depth': [15, 16, 17, 10, 11, 12],
'Value':[100, 200, 300, 200, 300, 400]})
counter = 0.0
def add(val):
global counter
if counter <=0.9:
val = val counter
counter =0.1
return val
else:
counter=0.1
return val
# Duplicate each rows 10 times and sort using the index
df = pd.concat([df]*10).sort_index()
# Apply add function on the depth
df['Depth'] = df['Depth'].apply(add)
# Reset the index
df= df.reset_index(drop=True)
# Increment the value by 10 based on the last value
for idx in range(1,len(df)):
df.loc[idx, 'Value'] = df.loc[idx-1,'Value'] 10
Output:
Name Depth Value
0 AS 15.0 100
1 AS 15.1 110
2 AS 15.2 120
3 AS 15.3 130
4 AS 15.4 140
5 AS 15.5 150
6 AS 15.6 160
7 AS 15.7 170
8 AS 15.8 180
9 AS 15.9 190
10 AS 16.0 200
11 AS 16.1 210
12 AS 16.2 220
13 AS 16.3 230
14 AS 16.4 240