I have a dictionary containing nested lists of dictionaries that I want to flatten and unpack to a csv file. The keys of the initial dictionary (called 'readings') are a list of physical place identitifers (e.g. 111, 222, etc.)
list_of_attributes = readings.keys()
print(list_of_attributes)
result:
dict_keys(['000111', '000967', '000073' ...
For every key there is a nested list of further dictionaries containing time-series like data:
list(readings.values())[0]
[{'Approval': {'ApprovalLevel': 650, 'LevelDescription': 'Working'},
'FieldVisitIdentifier': '2a328f51-aac7-494d-9f08-69716a06b179',
'Value': {'Unit': 'ft', 'Numeric': -1.53},
'DatumConvertedValues': [{'TargetDatum': 'NAVD88',
'Unit': 'ft',
'Numeric': 4.196010479999999},
{'TargetDatum': 'NGVD29', 'Unit': 'ft', 'Numeric': 4.779999999999999},
{'TargetDatum': 'Local Assumed Datum', 'Unit': 'ft', 'Numeric': -0.28}],
'Parameter': 'GWL',
'MonitoringMethod': 'Steel Tape',
'Time': '2021-05-25T18:51:00.0000000 00:00',
'Comments': 'MP = hole in top of SS = 1.25 ft LSD',
'Publish': True,
'ReadingType': 'Routine',
'ReferencePointUniqueId': '13208d3d0fe846c08ba7d6777b040433',
'UseLocationDatumAsReference': False},
...
I've had some success in using Amir Ziai's flatten_json package to flatten and unpack the nested lists of dictionaries out to a csv with the following:
data = {(k, i): flatten(item) for k, v in readings.items() for i, item in enumerate(v)}
df = pd.DataFrame.from_dict(data, orient='index')
df.to_csv(r"C:\test.csv", index=False)
Resultant csv:
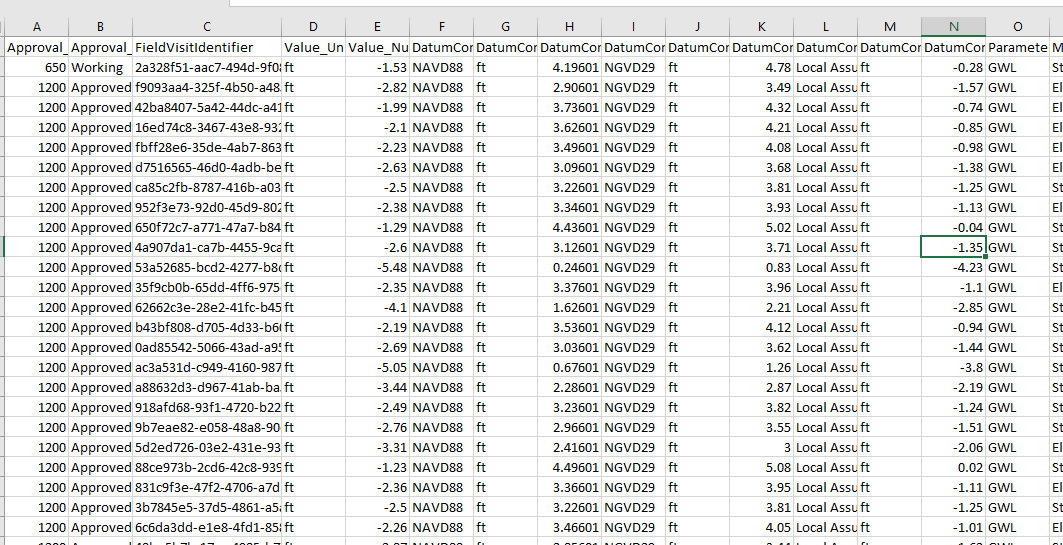
This is exactly what I want but I also need to somehow map the intial keys ('000111', '000967', '000073' ) to a column for every associated record. That would look like this
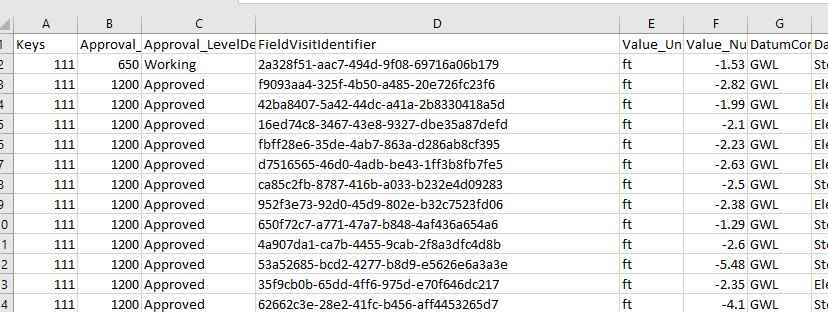
UPDATE: json sample from endpoint
Response Body
{
"FieldVisitReadings": [
{
"Approval": {
"ApprovalLevel": 650,
"LevelDescription": "Working"
},
"FieldVisitIdentifier": "2a328f51-aac7-494d-9f08-69716a06b179",
"Value": {
"Unit": "ft",
"Numeric": -1.53
},
"DatumConvertedValues": [
{
"TargetDatum": "NAVD88",
"Unit": "ft",
"Numeric": 4.196010479999999
},
{
"TargetDatum": "NGVD29",
"Unit": "ft",
"Numeric": 4.779999999999999
},
{
"TargetDatum": "Local Assumed Datum",
"Unit": "ft",
"Numeric": -0.28
}
],
"Parameter": "GWL",
"MonitoringMethod": "Steel Tape",
"Time": "2021-05-25T18:51:00.0000000 00:00",
"Comments": "MP = hole in top of SS = 1.25 ft LSD",
"Publish": true,
"ReadingType": "Routine",
"ReferencePointUniqueId": "13208d3d0fe846c08ba7d6777b040433",
"UseLocationDatumAsReference": false
},
UPDATE 2:
# Step 1: Fetch the list of locations
locationDescriptions = client.publish.get('/GetLocationist')['LocationDescriptions']
#Pass list of identifiders to 2nd endpoint and create dictionary. Keys are list of locations from Step 1
readings = dict(
(loc['Identifier'],
client.publish.get('/GetReadingsByLocation', params={
'LocationIdentifier': loc['Identifier'],
'Parameters': ['GWL'],
'ApplyDatumConversion': 'true'
})['FieldVisitReadings']
) for loc in locationDescriptions)
CodePudding user response:
You can use DataFrame.drop_level() DataFrame.reset_index() to get your column:
import pandas as pd
from flatten_json import flatten
readings = {
"000111": [
{
"Approval": {"ApprovalLevel": 650, "LevelDescription": "Working"},
"FieldVisitIdentifier": "2a328f51-aac7-494d-9f08-69716a06b179",
"Value": {"Unit": "ft", "Numeric": -1.53},
"DatumConvertedValues": [
{
"TargetDatum": "NAVD88",
"Unit": "ft",
"Numeric": 4.196010479999999,
},
{
"TargetDatum": "NGVD29",
"Unit": "ft",
"Numeric": 4.779999999999999,
},
{
"TargetDatum": "Local Assumed Datum",
"Unit": "ft",
"Numeric": -0.28,
},
],
"Parameter": "GWL",
"MonitoringMethod": "Steel Tape",
"Time": "2021-05-25T18:51:00.0000000 00:00",
"Comments": "MP = hole in top of SS = 1.25 ft LSD",
"Publish": True,
"ReadingType": "Routine",
"ReferencePointUniqueId": "13208d3d0fe846c08ba7d6777b040433",
"UseLocationDatumAsReference": False,
},
{
"Approval": {"ApprovalLevel": 1200, "LevelDescription": "Working"},
"FieldVisitIdentifier": "xxx",
"Value": {"Unit": "ft", "Numeric": -1.53},
"DatumConvertedValues": [
{
"TargetDatum": "NAVD88",
"Unit": "ft",
"Numeric": 4.196010479999999,
},
{
"TargetDatum": "NGVD29",
"Unit": "ft",
"Numeric": 4.779999999999999,
},
{
"TargetDatum": "Local Assumed Datum",
"Unit": "ft",
"Numeric": -0.28,
},
],
"Parameter": "GWL",
"MonitoringMethod": "Steel Tape",
"Time": "2021-05-25T18:51:00.0000000 00:00",
"Comments": "MP = hole in top of SS = 1.25 ft LSD",
"Publish": True,
"ReadingType": "Routine",
"ReferencePointUniqueId": "13208d3d0fe846c08ba7d6777b040433",
"UseLocationDatumAsReference": False,
},
]
}
data = {
(k, i): flatten(item)
for k, v in readings.items()
for i, item in enumerate(v)
}
df = pd.DataFrame.from_dict(data, orient="index")
df = df.droplevel(level=1).reset_index().rename(columns={"index": "Keys"})
print(df)
df.to_csv("data.csv", index=False)
Prints:
Keys Approval_ApprovalLevel Approval_LevelDescription FieldVisitIdentifier Value_Unit Value_Numeric DatumConvertedValues_0_TargetDatum DatumConvertedValues_0_Unit DatumConvertedValues_0_Numeric DatumConvertedValues_1_TargetDatum DatumConvertedValues_1_Unit DatumConvertedValues_1_Numeric DatumConvertedValues_2_TargetDatum DatumConvertedValues_2_Unit DatumConvertedValues_2_Numeric Parameter MonitoringMethod Time Comments Publish ReadingType ReferencePointUniqueId UseLocationDatumAsReference
0 000111 650 Working 2a328f51-aac7-494d-9f08-69716a06b179 ft -1.53 NAVD88 ft 4.19601 NGVD29 ft 4.78 Local Assumed Datum ft -0.28 GWL Steel Tape 2021-05-25T18:51:00.0000000 00:00 MP = hole in top of SS = 1.25 ft LSD True Routine 13208d3d0fe846c08ba7d6777b040433 False
1 000111 1200 Working xxx ft -1.53 NAVD88 ft 4.19601 NGVD29 ft 4.78 Local Assumed Datum ft -0.28 GWL Steel Tape 2021-05-25T18:51:00.0000000 00:00 MP = hole in top of SS = 1.25 ft LSD True Routine 13208d3d0fe846c08ba7d6777b040433 False
and saves data.csv:
