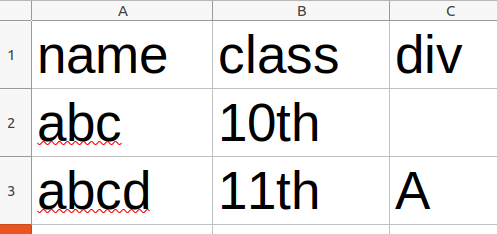
I need to store list of objects whose number of keys are not fixed in CSV file.
Example :
suppose I have a object
obj1 = { "name": "abc", "class" : "10th" }
obje2 = { "name": "abcd", "class" : "11th", "div" : "A" }
So There will be common elements, but I need to store all the elements
My output would be like this :
CodePudding user response:
Sure thing. You'll just have to gather up all of the keys first – that's done with set unions – and then feed the data to a csv.DictWriter.
import csv
import sys
data = [
{"name": "abc", "class": "10th"},
{"name": "abcd", "class": "11th", "div": "A"},
{"name": "qweabcd", "class": "11th", "diy": "Q"},
]
all_keys = set()
for obj in data:
all_keys |= set(obj)
writer = csv.DictWriter(sys.stdout, sorted(all_keys))
writer.writeheader()
for obj in data:
writer.writerow(obj)
This outputs
class,div,diy,name
10th,,,abc
11th,A,,abcd
11th,,Q,qweabcd
Since sets don't have an intrinsic order, I'm using sorted to sort the keys alphabetically.
If you need a specific order, that can be done with a custom key function to sorted.
key_order = ["name", "class"]
def get_key_sort_value(key):
if key in key_order:
return (0, key_order.index(key))
return (1, key)
writer = csv.DictWriter(sys.stdout, sorted(all_keys, key=get_key_sort_value))
# ...
will sort name and class first, followed by other keys in alphabetical order.
CodePudding user response:
Another solution, with pandas:
import pandas as pd
obj1 = {"name": "abc", "class": "10th"}
obj2 = {"name": "abcd", "class": "11th", "div": "A"}
df = pd.DataFrame([obj1, obj2])
print(df)
df.to_csv("data.csv", index=False)
Prints:
name class div
0 abc 10th NaN
1 abcd 11th A
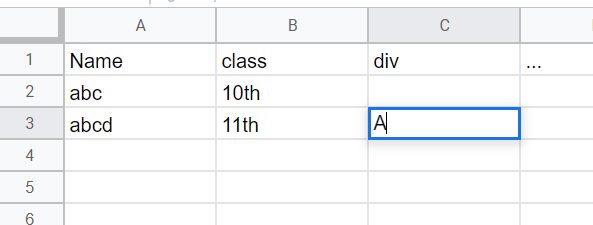
and saves data.csv (screenshot from LibreOffice):