i have a problem with my jupyter notebook. I wanna add a csv-file to my project but i get following error:
df = pd.read_csv("C:/Users/Jens/Projektarbeit - Ticket Intelligence/train_mail.csv")df = pd.read_csv("C:/Users/Jens/Projektarbeit - Ticket Intelligence/train_mail.csv")
ParserError
Traceback (most recent call last)
<ipython-input-18-1e20204919e4> in <module>
1 import pandas as pd
2
----> 3 df = pd.read_csv("C:/Users/Jens/Projektarbeit - Ticket Intelligence/train_mail.csv")
~\anaconda3\lib\site-packages\pandas\io\parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
684 )
685
--> 686 return _read(filepath_or_buffer, kwds)
687
688
~\anaconda3\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds)
456
457 try:
--> 458 data = parser.read(nrows)
459 finally:
460 parser.close()
~\anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows)
1194 def read(self, nrows=None):
1195 nrows = _validate_integer("nrows", nrows)
-> 1196 ret = self._engine.read(nrows)
1197
1198 # May alter columns / col_dict
~\anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows)
2153 def read(self, nrows=None):
2154 try:
-> 2155 data = self._reader.read(nrows)
2156 except StopIteration:
2157 if self._first_chunk:
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.read()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_low_memory()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_rows()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._tokenize_rows()
pandas\_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error()
ParserError: Error tokenizing data. C error: Expected 5 fields in line 16, saw 6
CodePudding user response:
This error may be due to a faulty input line in the file. Use the following to drop the lines of this sort.
df = pd.read_csv("C:/Users/Jens/Projektarbeit - Ticket Intelligence/train_mail.csv", error_bad_lines=False)
CodePudding user response:

b'Skipping line 16: expected 5 fields, saw 6\nSkipping line 45: expected 5 fields, saw 6\nSkipping line 67: expected 5 fields, saw 6\nSkipping line 79: expected 5 fields, saw 7\nSkipping line 112: expected 5 fields, saw 7\nSkipping line 118: expected 5 fields, saw 6\nSkipping line 135: expected 5 fields, saw 6\nSkipping line 144: expected 5 fields, saw 7\nSkipping line 189: expected 5 fields, saw 6\nSkipping line 204: expected 5 fields, saw 6\nSkipping line 213: expected 5 fields, saw 6\nSkipping line 215: expected 5 fields, saw 6\nSkipping line 308: expected 5 fields, saw 6\nSkipping line 343: expected 5 fields, saw 6\nSkipping line 347: expected 5 fields, saw 6\nSkipping line 468: expected 5 fields, saw 7\nSkipping line 552: expected 5 fields, saw 6\n'
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_tokens()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_with_dtype()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._string_convert()
pandas\_libs\parsers.pyx in pandas._libs.parsers._string_box_utf8()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xfc in position 27: invalid start byte
During handling of the above exception, another exception occurred:
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-37-cb5661f8780a> in <module>
----> 1 df = pd.read_csv("C:/Users/Jens/Projektarbeit - Ticket Intelligence/train_mail.csv", error_bad_lines=False)
~\anaconda3\lib\site-packages\pandas\io\parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
684 )
685
--> 686 return _read(filepath_or_buffer, kwds)
687
688
~\anaconda3\lib\site-packages\pandas\io\parsers.py in _read(filepath_or_buffer, kwds)
456
457 try:
--> 458 data = parser.read(nrows)
459 finally:
460 parser.close()
~\anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows)
1194 def read(self, nrows=None):
1195 nrows = _validate_integer("nrows", nrows)
-> 1196 ret = self._engine.read(nrows)
1197
1198 # May alter columns / col_dict
~\anaconda3\lib\site-packages\pandas\io\parsers.py in read(self, nrows)
2153 def read(self, nrows=None):
2154 try:
-> 2155 data = self._reader.read(nrows)
2156 except StopIteration:
2157 if self._first_chunk:
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.read()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_low_memory()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_rows()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_column_data()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_tokens()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_with_dtype()
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._string_convert()
pandas\_libs\parsers.pyx in pandas._libs.parsers._string_box_utf8()
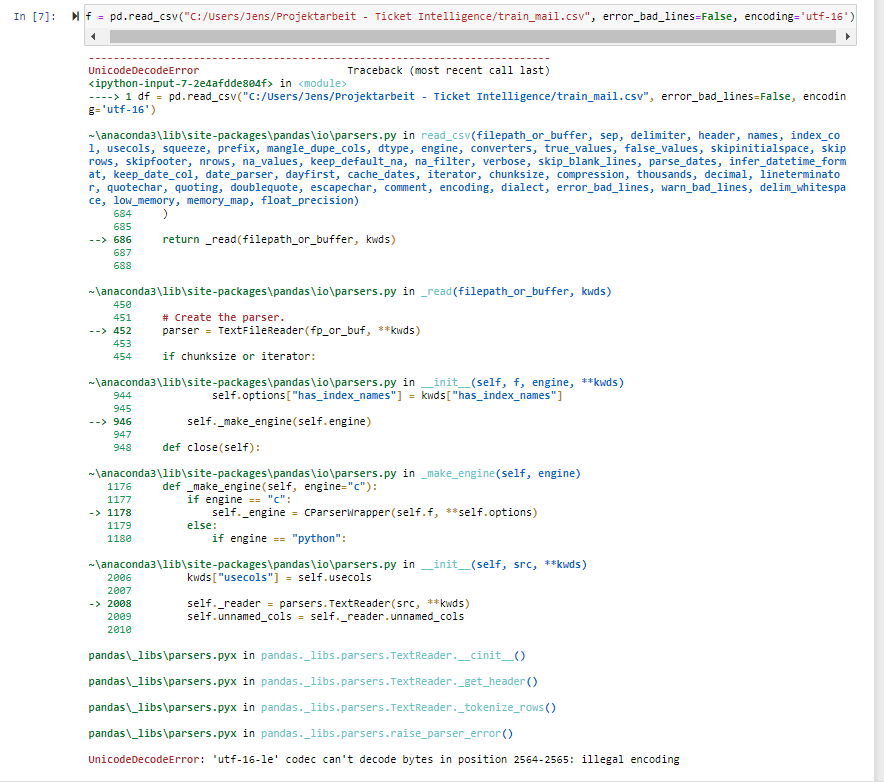
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xfc in position 27: invalid start byte