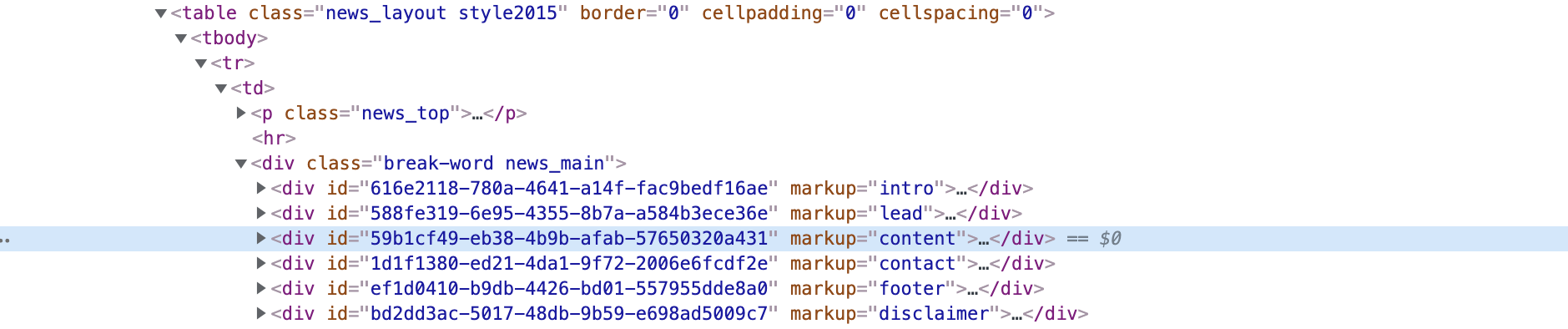
I would like to scrape text from a website using Beautifulsoup.
From the code which can be seen in the screenshot above, I would like to retrieve the text stored under markup="content".
I know how to retrieve all markup-parts using soup.find("div", class_="break-word news_main"). But I don't know how to only access the markup="content"-part.
Help would be very much appreciated :)
(Also, is markup a special term in html like "class" or "id"? What does "markup" mean?)
CodePudding user response:
soup.find_all(markup="content"), as you can see you can filter by any attribute. See docs for more details. markup is some kind of custom attribute; it's not a valid attribute for div elements but you can technically have any attribute on an element and it will still work, both in HTML and in BeautifulSoup.
CodePudding user response:
You can use soup.find_all(markup='content') or a different syntax is soup.find_all('div', {'markup': 'content'} which will give you all divs that contain the attribute mark up with a value of content.
Markup can mean quite a few things. It's basically a system for stylizing text. You can see more here. In this context it's probably something used to style html on a webpage.