I tried to extract URL from a hyperlink in this web: 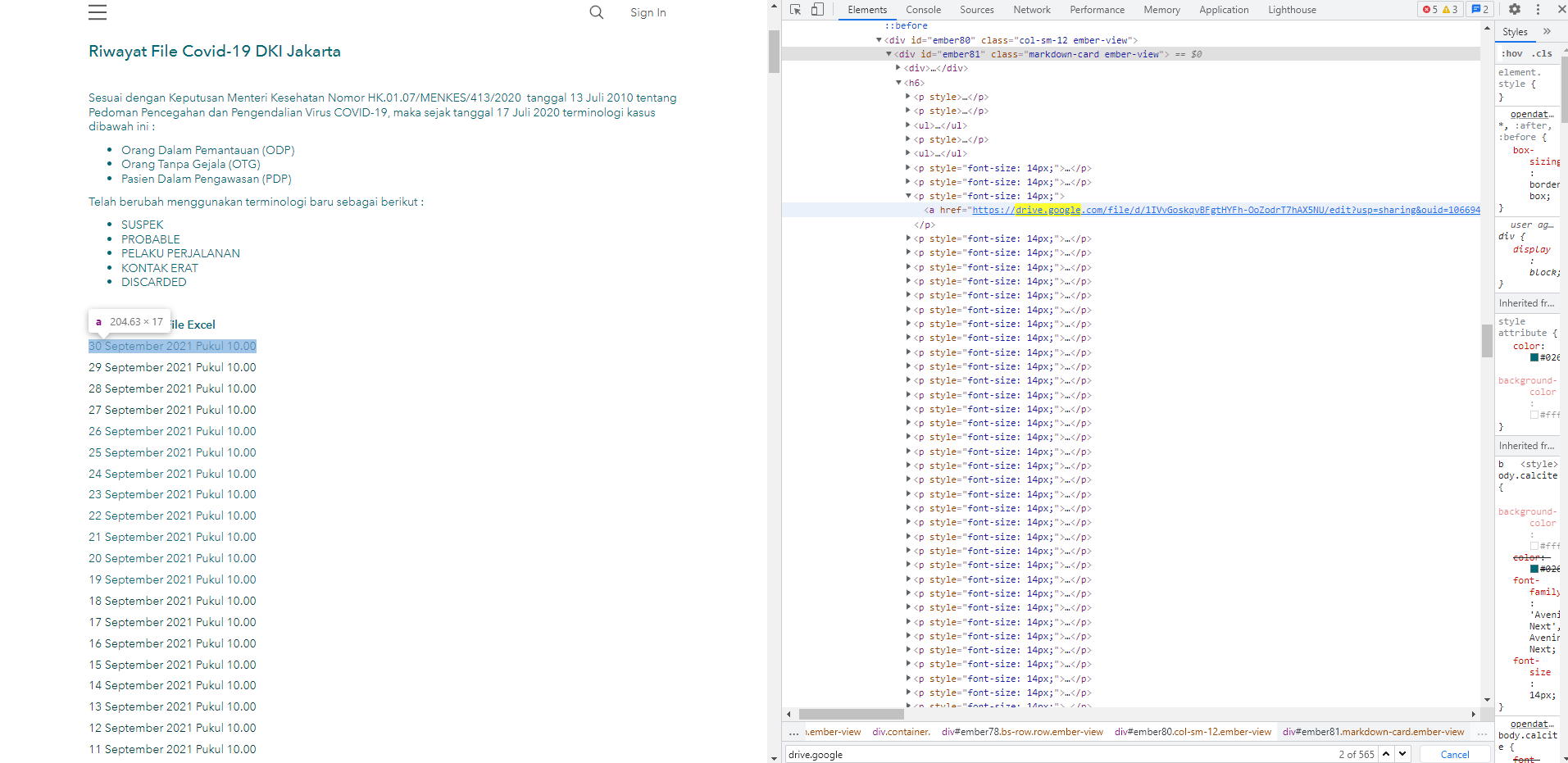
CodePudding user response:
You are unable to parse it as the data is dynamically loaded. As you can see in the following image, the HTML data that is being written to the page doesn't actually exist when you download the HTML source code. The JavaScript later parses the window.__SITE variable and extracts the data from there:

However, we can replicate this in Python. After downloading the page:
import requests
url = "https://riwayat-file-covid-19-dki-jakarta-jakartagis.hub.arcgis.com/"
req = requests.get(url)
You can use re (regex) to extract the encoded page source:
import re
encoded_data = re.search("window\.__SITE=\"(.*)\"", req.text).groups()[0]
Afterwards, you can use urllib to URL-decode the text, and json to parse the JSON string data:
from urllib.parse import unquote
from json import loads
json_data = loads(unquote(encoded_data))
You can then parse the JSON tree to get to the HTML source data:
html_src = json_data["site"]["data"]["values"]["layout"]["sections"][1]["rows"][0]["cards"][0]["component"]["settings"]["markdown"]
At that point, you can use your own code to parse the HTML:
soup = BeautifulSoup(html_src, 'html.parser')
print(soup.prettify())
links = soup.find_all('a')
for link in links:
if "href" in link.attrs:
print(str(link.attrs['href']) "\n")
If you put it all together, here's the final script:
import requests
import re
from urllib.parse import unquote
from json import loads
from bs4 import BeautifulSoup
# Download URL
url = "https://riwayat-file-covid-19-dki-jakarta-jakartagis.hub.arcgis.com/"
req = requests.get(url)
# Get encoded JSON from HTML source
encoded_data = re.search("window\.__SITE=\"(.*)\"", req.text).groups()[0]
# Decode and load as dictionary
json_data = loads(unquote(encoded_data))
# Get the HTML source code for the links
html_src = json_data["site"]["data"]["values"]["layout"]["sections"][1]["rows"][0]["cards"][0]["component"]["settings"]["markdown"]
# Parse it using BeautifulSoup
soup = BeautifulSoup(html_src, 'html.parser')
print(soup.prettify())
# Get links
links = soup.find_all('a')
# For each link...
for link in links:
if "href" in link.attrs:
print(str(link.attrs['href']) "\n")
CodePudding user response:
The links are generated dynamically by javascript code and the data can be found un the structure below.
<script id="site-injection">
window.__SITE="your data is here"
</script>
So you need to grab this script element and parse the value of window.__SITE
CodePudding user response:
The website takes time to load because data is generating by javascript which is asynchronous. That's why I use selenium with bs4 to grab the dynamic data. You have to give some loading time.
So, You can use time.sleep() or explicit waits. Here I'm using time.sleep()
CODE:
from bs4 import BeautifulSoup
import time
from selenium import webdriver
driver = webdriver.Chrome('chromedriver.exe')
driver.maximize_window()
time.sleep(8)
url = 'https://riwayat-file-covid-19-dki-jakarta-jakartagis.hub.arcgis.com/'
driver.get(url)
time.sleep(10)
soup = BeautifulSoup(driver.page_source, 'html.parser')
#print(soup.prettify())
links = soup.find_all('a')
for link in links:
if "href" in link.attrs:
print(str(link.attrs['href']) "\n")
driver.close()
OUTPUT:
https://drive.google.com/file/d/1xqtplGp_kFKXecUPTnplTjs0tKjO5PWD/view?usp=sharing
https://drive.google.com/file/d/1MJY9VuCntv5-BE3PYWVnkjSZ26GBTLon/view?usp=sharing
https://drive.google.com/file/d/1m7tklCfx-3hBMVy-0fsmLfVLZCSz56ps/view?usp=sharing
https://drive.google.com/file/d/1PcOO50ehsH3S4EatfZBUYRuIDfCbKk9q/view?usp=sharing
https://drive.google.com/file/d/1vakk7_pduP2Qvk-MLZz-CCMh1CjkYYaS/view?usp=sharing
https://drive.google.com/file/d/1Up7yNlXi3TGjmsl7gvhJxUKBPIPSFEG6/view?usp=sharing
https://drive.google.com/file/d/1CcHI4Ug8cbmtb3w7jp3_2D5VNGJtgAVj/view?usp=sharing
https://drive.google.com/file/d/1Gfg7ueeWQvcf5P-FOTW15NyWMEYcQd_H/view?usp=sharing
https://drive.google.com/file/d/1Bwo2Eqpq8fSWeTopds-IxUkbHf-aH6pl/view?usp=sharing
https://drive.google.com/file/d/1gleg1PYvEfe7caM9p9WUqPw9H_Eb-2I6/view?usp=sharing
https://drive.google.com/file/d/1o0Zy2XOR3Q8HMXUemulIKxKnBnCz70kD/view?usp=sharing
https://drive.google.com/file/d/19SriuZwqzswpVoelNEjFKqhMtFTU9Icq/view?usp=sharing
https://drive.google.com/file/d/1c_Qsltr8uNTabQchMoAJ1Fr7XumeVVIt/view?usp=sharing
https://drive.google.com/file/d/1fKqwdl0Xe6iJspMoMaxGwDyTXBi33QMO/view?usp=sharing
https://drive.google.com/file/d/16SudF4yNPpPlqpBbCR-ajCc715XiJdw0/view?usp=sharing
https://drive.google.com/file/d/1v8qMUYfC70RCKf-Qn2TZdln5Su60j0Mg/view?usp=sharing
https://drive.google.com/file/d/1CcGb98_XR5T3cBseu2qdpmnxZVa2vB5t/view?usp=sharing
https://drive.google.com/file/d/17qXn4WdZMTeyrhoW6Ue-SpKyZkbC7f1s/view?usp=sharing
https://drive.google.com/file/d/19fc-8l4xDjtJDJeem4IwwM1VBgpqktWk/view?usp=sharing
https://drive.google.com/file/d/1GMe0rnbjiQF2OHyUtzHmI96z7Zd3lq-0/view?usp=sharing
https://drive.google.com/file/d/1TPdkNBronwjSXMHOWrM6P50ziysDA0EE/view?usp=sharing
https://drive.google.com/file/d/16i8rEnWGmUX-NysSR5ubF3hOywiAocot/view?usp=sharing
https://drive.google.com/file/d/1EpL25g_cHakolY9c2eZqqRrF6NNcPqFb/view?usp=sharing
https://drive.google.com/file/d/1pkonxdmVMv_sE7EFFExyBEhO1J_SPO8j/view?usp=sharing
https://drive.google.com/file/d/1qtkdxISjPkadJYS1qxjPLt4scqzKj9iy/view?usp=sharing
https://drive.google.com/file/d/1poga1-JipsMsaeOM6hIFELTKWA4F3ITe/view?usp=sharing
https://drive.google.com/file/d/1LhAzj7BywHRjY5ul3TJNmUlhPM-9WcSz/view?usp=sharing
https://drive.google.com/file/d/1yD08Ml12fwrKdWbzwGHOhHZf1RsPbKll/view?usp=sharing
https://drive.google.com/file/d/1wdtEUilVn-wcANMXIBxK0Ys2qNEzFRHm/view?usp=sharing
https://drive.google.com/file/d/1yhEhP_XRb4ug4Zn2T33VlC4BE8qCRtLa/view?usp=sharing
https://drive.google.com/file/d/1UpxgtE6LbrwYEbg3pGUuQSK1auVx0Qju/view?usp=sharing
https://drive.google.com/file/d/1yLkCkTqR2-WAdF4mKypb6UOPtL-TINqU/view?usp=sharing
https://drive.google.com/file/d/12KiE0obOMo4T5SIkfSgSDfu5FAHXt_Oe/view?usp=sharing
https://drive.google.com/file/d/17KdjZUIapxNrJwwQ1P1MGiQOVqeCoNfd/view?usp=sharing
https://drive.google.com/file/d/10EwUfy78DNIJJLe8mL0bzYKQrqf-4qhv/view?usp=sharing
https://drive.google.com/file/d/1ciR9HxplDG8bj2DScUgc0z2G2zmhOwmt/view?usp=sharing
https://drive.google.com/file/d/1_UYCWEgMBIhhkhlTXfrlQEVcAvf5zPeP/view?usp=sharing
https://drive.google.com/file/d/1QtFm2uUVOoDdL8MFQI_hFg3hrQZgu5hv/view?usp=sharing
https://drive.google.com/file/d/1S0hifKlm3HpSyvYJmAIqX2lU2KT0cOsb/view?usp=sharing
... so on