I have text that I would like to parse into individual sections, along with the number heading that section. To see what I mean, I currently have something similar to the following script that parses out lines of text between numbers such as '1. ' or '10. '.
DECLARE @EXAMPLE TABLE (
ID INT
, COMMENT VARCHAR(8000)
)
DECLARE
@olddelim1 VARCHAR(MAX) = '1. '
,@olddelim2 VARCHAR(MAX) = '2. '
,@olddelim3 VARCHAR(MAX) = '3. '
,@olddelim4 VARCHAR(MAX) = '4. '
,@olddelim5 VARCHAR(MAX) = '5. '
,@olddelim6 VARCHAR(MAX) = '6. '
,@olddelim7 VARCHAR(MAX) = '7. '
,@olddelim8 VARCHAR(MAX) = '8. '
,@olddelim9 VARCHAR(MAX) = '9. '
,@olddelim10 VARCHAR(MAX) = '0. '
,@newdelim VARCHAR(MAX) = '¦'
,@olddelim0 VARCHAR(MAX) = '¦¦'
INSERT INTO @EXAMPLE (ID, COMMENT)
VALUES
(1, '1. Sed ut perspiciatis 1.3 unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo. 2. Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt. 3. Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem 4. Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur 5. Quis autem vel eum iure reprehenderit qui in ea voluptate velit esse quam nihil molestiae consequatur, vel illum qui dolorem eum fugiat quo voluptas nulla pariatur?')
, (2, 'At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia 8.3 deserunt mollitia animi, id est laborum et dolorum fuga')
, (3, 'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua 1. A cras semper auctor neque 2. Morbi tincidunt augue interdum velit euismod in')
, (4, '1. Amet luctus venenatis lectus magna 2. Magna ac placerat vestibulum lectus mauris ultrices eros in cursus 3. Et ligula ullamcorper malesuada proin libero nunc consequat interdum varius 4. Enim facilisis gravida neque convallis a 5. Sed lectus vestibulum mattis ullamcorper velit sed 6. Vel turpis nunc eget lorem dolor 7. Convallis convallis tellus id interdum velit laoreet id donec 8. Nibh tortor id aliquet lectus proin nibh nisl 9. Eu ultrices vitae auctor eu augue ut 10. Mus mauris vitae ultricies leo integer malesuada nunc 11. Viverra justo nec 10.4 ultrices dui sapien eget mi 12. Tristique senectus et netus et malesuada fames ac turpis')
UPDATE @EXAMPLE
SET COMMENT = REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(COMMENT, @olddelim1,@newdelim),@olddelim2,@newdelim),@olddelim3,@newdelim),@olddelim4,@newdelim),@olddelim5,@newdelim),@olddelim6,@newdelim),@olddelim7,@newdelim),@olddelim8,@newdelim),@olddelim9,@newdelim),@olddelim10,@newdelim),@olddelim0,@newdelim)
;WITH SPLIT_TABLE(ID, STARTS, POS, FOUND_SECTIONS) AS (
SELECT
ID
, 1
, CHARINDEX('¦', COMMENT)
, COMMENT
FROM @EXAMPLE
UNION ALL
SELECT
ID
, POS 1
, CHARINDEX('¦', FOUND_SECTIONS, POS 1)
, FOUND_SECTIONS
FROM SPLIT_TABLE
WHERE POS > 0)
, FOUND_SECTIONS_TBL(ID, FOUND_SECTIONS) AS (
SELECT
ID
, SUBSTRING(FOUND_SECTIONS, STARTS, CASE WHEN POS > 0 THEN POS - STARTS ELSE LEN(FOUND_SECTIONS) END)
FROM SPLIT_TABLE)
SELECT * FROM FOUND_SECTIONS_TBL
WHERE FOUND_SECTIONS <> ''
ORDER BY ID
However, what I would like to see is that the number I'm extracting stay associated to that section of text. However, I cannot simply do this with something like a ROW_NUMBER() over the STARTS/POS fields, as there are strings that do not initially start with a number (e.g. ID = 3). So the end result would look something like this:
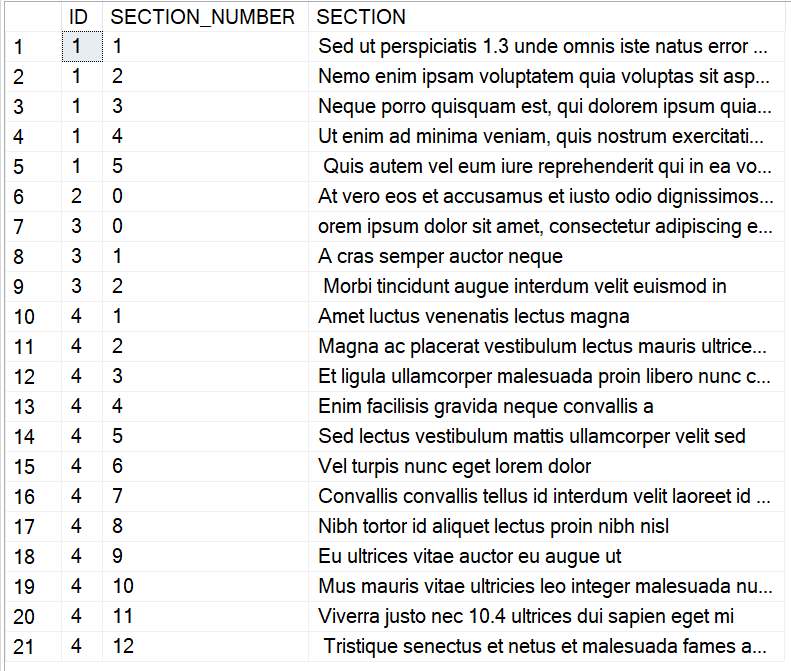
CREATE TABLE #RESULTS (ID INT, SECTION_NUMBER INT, SECTION VARCHAR(8000))
INSERT INTO #RESULTS
VALUES
(1,1,'Sed ut perspiciatis 1.3 unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo.')
,(1,2,'Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt.')
,(1,3,'Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem')
,(1,4,'Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur')
,(1,5,'Quis autem vel eum iure reprehenderit qui in ea voluptate velit esse quam nihil molestiae consequatur, vel illum qui dolorem eum fugiat quo voluptas nulla pariatur?')
,(2,0,'At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia 8.3 deserunt mollitia animi, id est laborum et dolorum fuga')
,(3,0,'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua')
,(3,1,'A cras semper auctor neque')
,(3,2,'Morbi tincidunt augue interdum velit euismod in')
,(4,1,'Amet luctus venenatis lectus magna')
,(4,2,'Magna ac placerat vestibulum lectus mauris ultrices eros in cursus')
,(4,3,'Et ligula ullamcorper malesuada proin libero nunc consequat interdum varius')
,(4,4,'Enim facilisis gravida neque convallis a ')
,(4,5,'Sed lectus vestibulum mattis ullamcorper velit sed')
,(4,6,'Vel turpis nunc eget lorem dolor')
,(4,7,'Convallis convallis tellus id interdum velit laoreet id donec')
,(4,8,'Nibh tortor id aliquet lectus proin nibh nisl')
,(4,9,'Eu ultrices vitae auctor eu augue ut')
,(4,10,'Mus mauris vitae ultricies leo integer malesuada nunc')
,(4,11,'Viverra justo nec')
,(4,12,'Tristique senectus et netus et malesuada fames ac turpis')
SELECT * FROM #RESULTS DROP TABLE #RESULTS
I've tried replacing my nested REPLACE statement with variations of the STUFF function, and even combinations of the STUFF/REPLACE functions, but I can't quite get it to work the way I want it to. Does anyone have ideas about how to do this? Thanks!
CodePudding user response:
Note! Assuming that I understood your request, then The solution is simple using STRING_SPLIT function, but this is not something that you should do in production probably s the performance are really poor. This type of task are better do in the client side.
DDL DML
CREATE TABLE EXAMPLE (
ID INT
, COMMENT VARCHAR(8000)
)
INSERT INTO EXAMPLE (ID, COMMENT)
VALUES
(1, '1. Sed ut perspiciatis 1.3 unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo. 2. Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt. 3. Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem 4. Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur 5. Quis autem vel eum iure reprehenderit qui in ea voluptate velit esse quam nihil molestiae consequatur, vel illum qui dolorem eum fugiat quo voluptas nulla pariatur?')
, (2, 'At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia 8.3 deserunt mollitia animi, id est laborum et dolorum fuga')
, (3, 'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua 1. A cras semper auctor neque 2. Morbi tincidunt augue interdum velit euismod in')
, (4, '1. Amet luctus venenatis lectus magna 2. Magna ac placerat vestibulum lectus mauris ultrices eros in cursus 3. Et ligula ullamcorper malesuada proin libero nunc consequat interdum varius 4. Enim facilisis gravida neque convallis a 5. Sed lectus vestibulum mattis ullamcorper velit sed 6. Vel turpis nunc eget lorem dolor 7. Convallis convallis tellus id interdum velit laoreet id donec 8. Nibh tortor id aliquet lectus proin nibh nisl 9. Eu ultrices vitae auctor eu augue ut 10. Mus mauris vitae ultricies leo integer malesuada nunc 11. Viverra justo nec 10.4 ultrices dui sapien eget mi 12. Tristique senectus et netus et malesuada fames ac turpis')
GO
SELECT * FROM EXAMPLE
GO
Optional solution
Please check if this solve your needs:
;With MyCTE as (
select ID, c =
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(COMMENT, '11. ', '@11# ')
, '12. ', '@12# '
)
, '13. ', '@13# '
)
, '4. ', '@4# '
)
, '5. ', '@5# '
)
, '6. ', '@6# '
)
, '7. ', '@7# '
)
, '8. ', '@8# '
)
, '9. ', '@9# '
)
, '10. ', '@10# '
)
, '1. ', '@1# '
)
, '2. ', '@2# '
)
, '3. ', '@3# '
)
FROM EXAMPLE
)
select ID,REPLACE(ISNULL(V.n,0),'# ','') as SECTION_NUMBER ,RIGHT([value], LEN([value]) - CHARINDEX('# ',[value],1)) as SECTION
from MyCTE
CROSS APPLY STRING_SPLIT(c,'@')
Left Join (values ('1# '),('2# '),('3# '),('4# '),('5# '),('6# '),('7# '),('8# '),('9# '),('10# '),('11# '),('12# '),('13# ')) V(n) ON [value] like V.n '%'
where NOT ISNULL([value],'') = ''
GO
Comments
(1) For the sake of the demo, I manually used the numbers 1-6 but in your production you might have many more numbers. You can use dynamic query in order to build the query dynamically. With that being said, for most cases, It is HIGHLY recommended not to be lazy (at least if the amount of numbers is too high) and use this approach of manually write nested REPLACE since dynamic query might reduce performance.
(2) SQL Server does not deal parsing text well and using multiple string functions is usually not recommended. Using SQL CLR you can gain much better result probably by using regular expression.
(3) In general you should avoid such task in the server side. SQL Server is a database management application and as such it is designed for best performance in managing the data and not parsing the data.
CodePudding user response:
After some research and elbow grease, I've come up with the solution below. I am not sure how performant/optimized it is, and I'm certain there's probably better ways to do this. However, I wanted to avoid hard-coding the numbers... So here it is:
CREATE TABLE #EXAMPLE (
ID INT
, COMMENT VARCHAR(8000)
)
INSERT INTO #EXAMPLE (ID, COMMENT)
VALUES
(1, '1. Sed ut perspiciatis 1.3 unde omnis iste natus error sit voluptatem accusantium doloremque laudantium, totam rem aperiam, eaque ipsa quae ab illo inventore veritatis et quasi architecto beatae vitae dicta sunt explicabo. 2. Nemo enim ipsam voluptatem quia voluptas sit aspernatur aut odit aut fugit, sed quia consequuntur magni dolores eos qui ratione voluptatem sequi nesciunt. 3. Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit, sed quia non numquam eius modi tempora incidunt ut labore et dolore magnam aliquam quaerat voluptatem 4. Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam, nisi ut aliquid ex ea commodi consequatur 5. Quis autem vel eum iure reprehenderit qui in ea voluptate velit esse quam nihil molestiae consequatur, vel illum qui dolorem eum fugiat quo voluptas nulla pariatur?')
, (2, 'At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident, similique sunt in culpa qui officia 8.3 deserunt mollitia animi, id est laborum et dolorum fuga')
, (3, 'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua 1. A cras semper auctor neque 2. Morbi tincidunt augue interdum velit euismod in')
, (4, '1. Amet luctus venenatis lectus magna 2. Magna ac placerat vestibulum lectus mauris ultrices eros in cursus 3. Et ligula ullamcorper malesuada proin libero nunc consequat interdum varius 4. Enim facilisis gravida neque convallis a 5. Sed lectus vestibulum mattis ullamcorper velit sed 6. Vel turpis nunc eget lorem dolor 7. Convallis convallis tellus id interdum velit laoreet id donec 8. Nibh tortor id aliquet lectus proin nibh nisl 9. Eu ultrices vitae auctor eu augue ut 10. Mus mauris vitae ultricies leo integer malesuada nunc 11. Viverra justo nec 10.4 ultrices dui sapien eget mi 12. Tristique senectus et netus et malesuada fames ac turpis')
GO
WITH PATTERNS AS (
SELECT
*
FROM (VALUES('%[0-9]. %', 3)
, ('%[0-9][0-9]. %', 4)
, ('%[0-9][0-9][0-9]. %', 5)) AS PATTERNS (PATTERN, LENGTH))
, L0 AS (SELECT C FROM (VALUES(1),(1)) AS D(C))
, L1 AS (SELECT 1 AS C FROM L0 AS A CROSS JOIN L0 AS B)
, L2 AS (SELECT 1 AS C FROM L1 AS A CROSS JOIN L1 AS B)
, L3 AS (SELECT 1 AS C FROM L2 AS A CROSS JOIN L2 AS B)
, L4 AS (SELECT 1 AS C FROM L3 AS A CROSS JOIN L3 AS B)
, NUMS AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS ROWNUM FROM L4)
, INDXS AS (
SELECT E.*, N.*, [GROUP] = DENSE_RANK() OVER(ORDER BY N.ROWNUM) - N.ROWNUM
FROM #EXAMPLE AS E
-- Outer apply so as to capture those without the pattern at all
OUTER APPLY (
SELECT *
FROM NUMS AS N
WHERE N.ROWNUM BETWEEN 1 AND LEN(E.COMMENT)
AND (EXISTS (
SELECT *
FROM PATTERNS AS P
WHERE PATINDEX(P.PATTERN, STUFF(E.COMMENT, 1, CASE WHEN N.ROWNUM > P.LENGTH THEN N.ROWNUM - P.LENGTH ELSE 0 END, '')) BETWEEN 1 AND CASE WHEN N.ROWNUM > P.LENGTH THEN P.LENGTH ELSE N.ROWNUM END)
-- For when there is no intial number at the beginning, but others at later indices
OR N.ROWNUM = 1 )) AS N
)
, PEN AS (
SELECT *, [RN] = ROW_NUMBER() OVER(PARTITION BY ID, [GROUP] ORDER BY ID, [GROUP], ROWNUM)
FROM INDXS
)
, FINAL AS (
SELECT F.ID, F.COMMENT, F.ROWNUM, [RN] = ROW_NUMBER() OVER(PARTITION BY F.ID ORDER BY F.ID, F.ROWNUM)
FROM PEN AS F
WHERE RN = 1
)
SELECT F.ID--, F.COMMENT, F.ROWNUM, N.ROWNUM
, [SECTION_NUMBER] = CASE WHEN N.ROWNUM IS NULL AND F.ROWNUM = 1 THEN 0 ELSE REPLACE(SUBSTRING((CASE WHEN N.ROWNUM IS NULL THEN SUBSTRING(F.COMMENT, F.ROWNUM, 8000) ELSE SUBSTRING(F.COMMENT, F.ROWNUM, N.ROWNUM - F.ROWNUM) END), 1, CHARINDEX('.', (CASE WHEN N.ROWNUM IS NULL THEN SUBSTRING(F.COMMENT, F.ROWNUM, 8000) ELSE SUBSTRING(F.COMMENT, F.ROWNUM, N.ROWNUM - F.ROWNUM) END), 1)), '.', '') END
, [SECTION] = (CASE WHEN N.ROWNUM IS NULL THEN SUBSTRING(F.COMMENT, F.ROWNUM, 8000) ELSE SUBSTRING(F.COMMENT, F.ROWNUM, N.ROWNUM - F.ROWNUM) END)
, F.ROWNUM
, N.ROWNUM
FROM FINAL AS F
LEFT OUTER JOIN FINAL AS N
ON F.ID = N.ID
AND F.RN = N.RN - 1
ORDER BY F.ID, F.ROWNUM
DROP TABLE #EXAMPLE
This solution was partially inspired by Ronen Ariely's answer as well as this post from SQLServerFast: https://sqlserverfast.com/blog/hugo/2019/04/removing-multiple-patterns-from-a-string/. It is able to hardcode the patterns I want to capture rather than all the individual instances of the pattern. I tried in particular to get this part to return only the starting index point of the number pattern (so if "2. " appears at points 233, 234, and 235, I only really want 233) but alas I could not figure that out. Interesting stuff, XML.
, INDXS AS (
SELECT E.*, N.*, [GROUP] = DENSE_RANK() OVER(ORDER BY N.ROWNUM) - N.ROWNUM
FROM #EXAMPLE AS E
-- Outer apply so as to capture those without the pattern at all
OUTER APPLY (
SELECT *
FROM NUMS AS N
WHERE N.ROWNUM BETWEEN 1 AND LEN(E.COMMENT)
AND (EXISTS (
SELECT *
FROM PATTERNS AS P
WHERE PATINDEX(P.PATTERN, STUFF(E.COMMENT, 1, CASE WHEN N.ROWNUM > P.LENGTH THEN N.ROWNUM - P.LENGTH ELSE 0 END, '')) BETWEEN 1 AND CASE WHEN N.ROWNUM > P.LENGTH THEN P.LENGTH ELSE N.ROWNUM END)
-- For when there is no intial number at the beginning, but others at later indices
OR N.ROWNUM = 1 )) AS N
)
In production, I had 335 rows I was applying this to, in which the "COMMENT" field was generally much longer than the sample data I used here. It took about 24 seconds, which works for me (this is for a one time report, but I may use it for similar requests).
Thanks to those who responded!