In the following minimal reproducible example, I want to make all the words in section [bar] lowercase:
[foo]
foo1=Hello World
[bar]
bar1=Hello World
bar2=Worldly Hello
The desired output is:
[foo]
foo1=Hello World
[bar]
bar1=hello world
bar2=worldly hello
To do this, I use the regular expression (regex) (.*?\[bar\].*?)([A-Z]) with a replacement string of $1\L$2.
In Notepad , I enable regex in the Find & Replace dialog box and also enable the Match case and . matches newline options.
Doing this, performing a Replace operation works as expected. I can then repeatedly hit the Replace button in Notepad over and over until reaching EOF to get the job done.
So now that this works, I want to create a reusable Notepad macro to end the tedium and perform the operation on the entire file.
My first idea was to simply use Replace All, but that won't work because the regex caret does not get reset after each replace operation when using Replace All.
How can my regex be improved to replace all [bar] section strings with lowercase values and have it work within a Notepad macro?
If it's not possible to improve my regex, I am willing to use another Notepad macro technique to perform this task.
The following is intended as context, and isn't required reading. Once I understand how to do the above, I can adapt what I learn to the following more complex case. But if you prefer to focus on this more complex case, that's great too.
I greatly simplified things for the example above. In my actual input files, there are multiple [sections] before and after the [bar] section. Also, I'm only wanting to apply lowercase to the first letter of all words that are not the first word in a string. That said, I have working code to accomplish all that, so if I get the greatly simplified example (above) working within a macro, I should have no problem adapting it for the much more complex real world case.
If you're interested in the more complex real world case, here is example input:
[foo]
foo1=Hello World
[bar]
bar1=Hello World
bar2=Worldly Hello
bar3=Worldly-Hello
bar4=worldly Hello
[baz]
baz1=Hello World
are here is the desired output:
[foo]
foo1=Hello World
[bar]
bar1=Hello world
bar2=Worldly hello
bar3=Worldly-hello
bar4=worldly hello
[baz]
baz1=Hello World
CodePudding user response:
In Notepad , there are several quirks that make such replacements harder than in other comparable environments.
You can match all words after [bar] section header and after each word followed with = using
Find What: (?:\G(?!^)|^\[bar])(?:\s*\R\w =|[^\w\r\n] )\K\w
Replace With: \L$0
See the 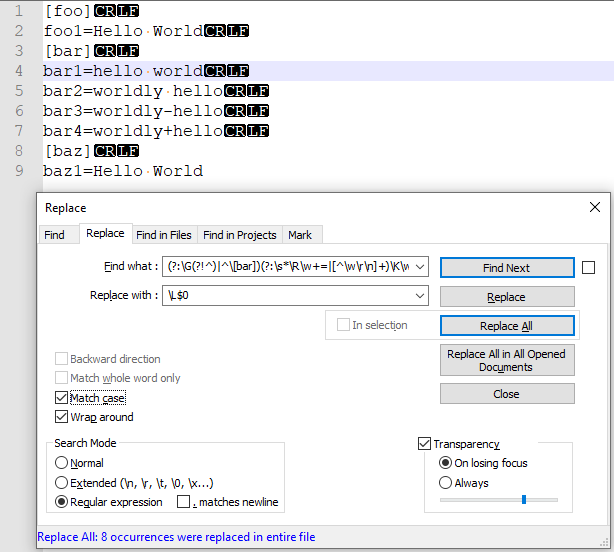
Regex details
(?:\G(?!^)|^\[bar])- either of the two: the end of the previous match (\G(?!^)) or (|)[bar]word (\[bar]) at the start of a line (^)(?:\s*\R\w =|[^\w\r\n] )- zero or more whitespaces, a line break sequence, one or more word chars,=(\s*\R\w =), or (|) any one or more chars other than word chars, CR and LF ([^\w\r\n])\K- a match reset operator that discards all text matched so far into the overall match memory buffer\w- one or more word chars ($0points to this value).