I want to select part of the title of the website.

after inspecting the title, the html code of the website looks like this:
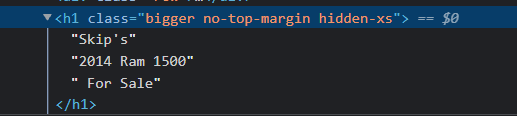
and i want to select only the "2014 Ram 1500" part. For this i wrote the following code:
# car name
try:
temp = driver.find_element_by_xpath(
'//*[@id="react"]/div/div/div[2]/div[5]/div[2]/div/h1[1]/text()[2]').text
data.append(temp)
except:
data.append('')
but i only getting a empty string(' '). I am using selenium for automation and copying the full Xpath of "2014 Ram 1500" in the code. What im doing wrong? And how i can i only select "2014 Ram 1500" part from the whole title?
CodePudding user response:
The text are in new line, you can split the string based on \n and from string array we could extract the first element.
try:
temp = driver.find_element_by_xpath('//*[@id="react"]/div/div/div[2]/div[5]/div[2]/div/h1[1]').text
a = temp.split('\n')[1]
print(a)
data.append(a)
except:
data.append('')
CodePudding user response:
Can you try like below and confirm.
temp = driver.find_element_by_xpath('//*[@id="react"]/div/div/div[2]/div[5]/div[2]/div/h1[1]/text()[2]').get_attribute("innerText")
CodePudding user response:
I wrote the below code and it actually worked. This time i copied the Xpath from h1 header and converted it in text. Then using slicing i got exactly what i wanted. Though i am not sure it is best practise or not:
# car name
try:
temp = driver.find_element_by_xpath('/html/body/section/div/div/div[2]/div[5]/div[2]/div/h1[1]').text
temp = temp.split()[1:-2]
temp = " ".join(e for e in temp)
data.append(temp)
except:
data.append('')