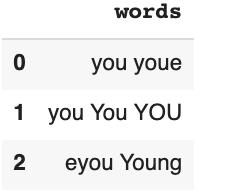
Suppose that this is the dataset that I am working on:
df1 = pd.DataFrame(['you youe', 'you You YOU', 'eyou Young'], columns=['words'])
print(df1)
I am hoping to count the frequency of strings 'you' and 'your' as words, regardless of what precedes or follows these strings and regardless the lower or upper cases.
I have put strings like 'youe' to test that my code doesn't miscount it.
this is what I have tried so far:
df1['counts']=df1['words'].str.count(' you|you. |you, |you | You | YOU|YOU. |YOU, |YOU|YOU | your|your | Your|Your | YOUR|YOUR ')
print(df1)
The expected output would be:
words count
0 you youe 1
1 you You YOU 3
2 eyou Young 0
But I am getting:
words count
0 you youe 1
1 you You YOU 2
2 eyou Young 1
CodePudding user response:
Use words boundaries by \b\b with optionaly match r, for not case sensitive test is possible add re.I flag:
import re
df1['new'] = df1['words'].str.count(r'\b(you[r]*)\b', flags=re.I)
print (df1)
words new
0 you youe 1
1 you Your YOU 3
2 eyou Young 0