I have time series dataframe, and want to compare two dataframes
(In detail, I need to check if dataframe is a subset of other dataframe.)
like that:
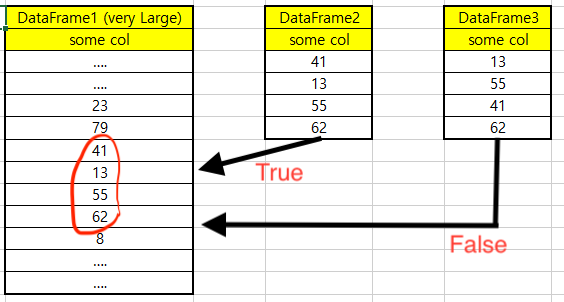
I've already tried to find a way, but I could only find it if it had the same value.
Is there a way to compare dataframes by checking the existence and order of values?
CodePudding user response:
This answer proposes converting the series in these data frames into Python arrays using Pandas' tolist() method and operating on these arrays instead. There may be more efficient versions of this answer if long sequences are involved. But if the inputs are short enough, then these will quickly arrive at the answer.
Note: This answer also assumes that the shorter array to be detected must be a contiguous of elements in the longer array.
List a is the shorter list to be scanned for in the longer lists b or c.
a = [41, 13, 55, 62]
b = [41, 13, 55, 62, 100]
c = [41, 8, 13, 55, 62]
def find_exact_short_seq_in_long_seq(short_l,long_l):
short_len = len(short_l)
long_len = len(long_l)
for i in range(0,long_len-short_len):
if short_l == long_l[i:i short_len]:
return True
return False
print("a,b",find_exact_short_seq_in_long_seq(a,b))
print("a,c",find_exact_short_seq_in_long_seq(a,c))
Output:
a,b True
a,c False
List a is found to be contained in list b but is not found to be contained in list c, as expected.
CodePudding user response:
You can try:
df_1 = pd.DataFrame(data={'same_col':[270, 271, 272, 273, 274]})
df_2 = pd.DataFrame(data={'same_col':[270, 271, 274]})
df_1.reset_index(inplace=True)
df_2 = df_2.merge(df_1[['same_col', 'index']], on=['same_col'])
print(df_2)
if ((df_2['index'] - df_2.index.to_series())==0).all():
print('Is subset')
else:
print('Not a subset')