I have my dataframe:
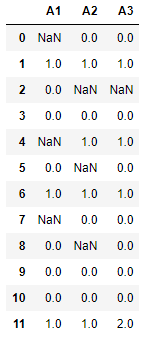
And I would like to create a subset of this dataframe with the columns in which there are the fewest NaN values (i.e. the most "valid" values)
In this case, I would only select the "A3" column as there is only one NaN and there are 3 in the others.
If there are two columns (or more) with the same number of NaN values, just select one of them (for example the first it does not matter).
The code for creating the dataframe:
df = pd.DataFrame({"A1":[np.NaN,1,0,0,np.NaN,0,1,np.NaN,0,0,0,1],
"A2":[0,1,np.NaN,0,1,np.NaN,1,0,np.NaN,0,0,1],
"A3":[0,1,np.NaN,0,1,0,1,0,0,0,0,2]})
df
CodePudding user response:
You can sum up the number of null values in each column using pd.isnull and .sum() , then pick the column with the lowest count using .idxmin() and select just that column from your dataframe:
df[pd.isnull(df).sum().idxmin()]
Output:
0 0.0
1 1.0
2 NaN
3 0.0
4 1.0
5 0.0
6 1.0
7 0.0
8 0.0
9 0.0
10 0.0
11 2.0
Name: A3, dtype: float64
CodePudding user response:
You can use pd.isnull(df['A']).sum() on your columns and work your way around with some logic to keep the column that has least NaNs in it.
Refer isnull() function
z = list()
for column in df:
z.append(pd.isnull(df[column]).sum())
list(df.iloc[:,z.index(min(z))].values)
[0.0, 1.0, nan, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 2.0]