I got this problem and have not idea how to do it with pandas, I know how to do it with openpyxl, but not with pandas. I provided a code below, I want to remove two rows and write something in a new cell.
import pandas as pd
import numpy as np
import string
index = pd.MultiIndex.from_product([[2020], [1, 2, 3, 4]],
names=['year', 'q'])
columns = pd.MultiIndex.from_product([['Items1', 'Items2', 'Items3'], ['new', 'old']],
names=['Items', 'type'])
data = np.random.seed(123)
data = list(np.random.choice(list(string.ascii_lowercase), (4,6)))
Ldata = pd.DataFrame(data, index=index, columns=columns)
Ldata
Now it's like this
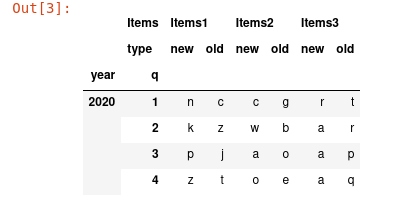
I want to remove second and third row, and to write a 'year' in first row first cell.
Like this
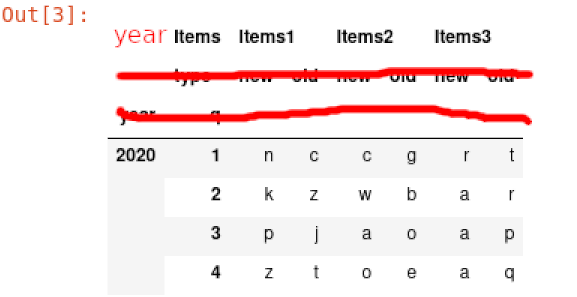
What is the best way to do this in pandas?
CodePudding user response:
You have multiindex columns. If you don't want to lose information but still merge the levels, the best option might be just to join different levels:
Ldata.columns = Ldata.columns.map('_'.join)
Ldata.reset_index(inplace=True)
Ldata
year q Items1_new Items1_old Items2_new Items2_old Items3_new Items3_old
0 2020 1 n c c g r t
1 2020 2 k z w b a r
2 2020 3 p j a o a p
3 2020 4 z t o e a q
CodePudding user response:
I think this should get you close:
Ldata.droplevel(axis=1, level=1).droplevel(axis=0, level=1)
You have multi-indexes (on both column and row) that can be dropped.