For pandas.merge(df1, df2, on='Col_4') will operate by inner join by default which will take rows on the shared columns that have the exact values in these shared columns.
Question: Let us say we have a 4 rows in first df1 and 3 rows in df2. So if all values in the shared columns are the same, then the first row will be added 4 times since we have, so we will have 10 rows for each row from dataframe1. In total, we will have 12 rows.
Problem: Is there a way to stop once we find a first match between the first and the second dataframe and move to the second row in the first dataframe please? However, we can not add the same match added to row 1 in df1 twice. So, suppose row 1 of df1 got matched to row 1 in df2 based on same value in shared column col_4, then the second row in df1 must be matched with second row of df2.

Code:
import pandas as pd
df1 = pd.DataFrame(
{
'ID':[1,2,3,5,9],
'col_1': [1,2,3,4,5],
'col_2':[6,7,8,9,10],
'col_3':[11,12,13,14,15],
'col_4':['apple', 'apple', 'apple', 'apple', 'apple']
}
)
df2 = pd.DataFrame(
{
'ID':[1,1,3,5],
'col_1': [8,9,10,11],
'col_2':[12,13,15,17],
'col_3':[12,13,14,15],
'col_4':['apple', 'apple', 'apple', 'apple']
}
)
pd.merge(df1, df2, on='col_4')
So, as below, how to stop please at first match as red rectangle show where we stop once we find a match from df1 to df2 based on shared column col_4 please? Output should be based on below figure please:
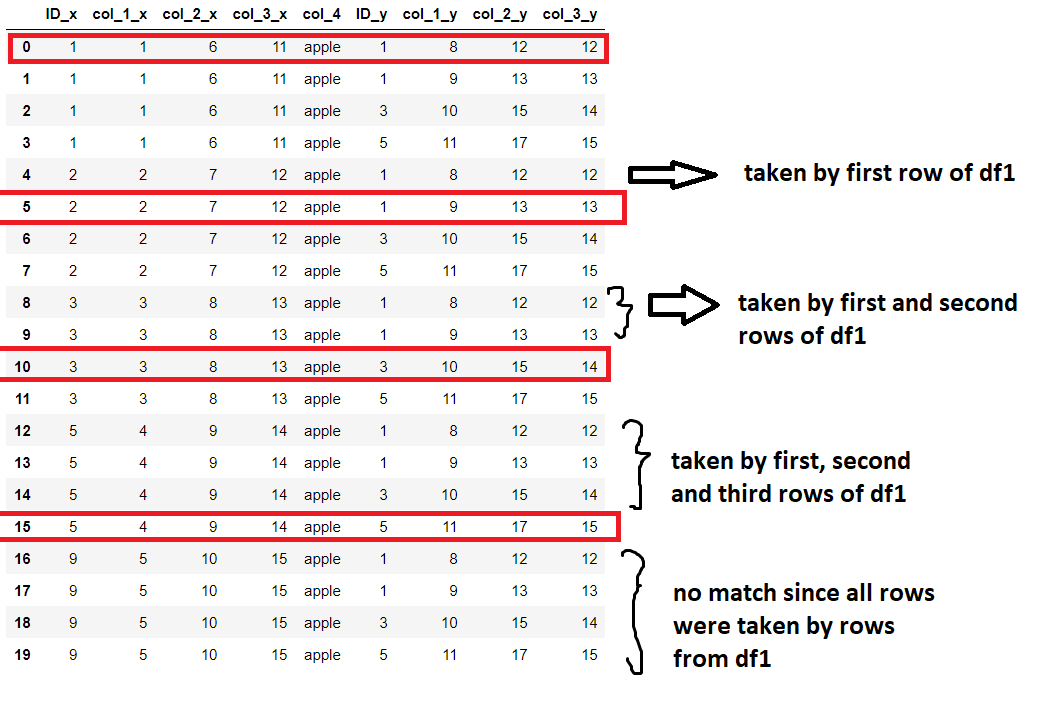
Results in dictionary format:
{'ID_x': {0: 1,
1: 1,
2: 1,
3: 1,
4: 2,
5: 2,
6: 2,
7: 2,
8: 3,
9: 3,
10: 3,
11: 3,
12: 5,
13: 5,
14: 5,
15: 5,
16: 9,
17: 9,
18: 9,
19: 9},
'col_1_x': {0: 1,
1: 1,
2: 1,
3: 1,
4: 2,
5: 2,
6: 2,
7: 2,
8: 3,
9: 3,
10: 3,
11: 3,
12: 4,
13: 4,
14: 4,
15: 4,
16: 5,
17: 5,
18: 5,
19: 5},
'col_2_x': {0: 6,
1: 6,
2: 6,
3: 6,
4: 7,
5: 7,
6: 7,
7: 7,
8: 8,
9: 8,
10: 8,
11: 8,
12: 9,
13: 9,
14: 9,
15: 9,
16: 10,
17: 10,
18: 10,
19: 10},
'col_3_x': {0: 11,
1: 11,
2: 11,
3: 11,
4: 12,
5: 12,
6: 12,
7: 12,
8: 13,
9: 13,
10: 13,
11: 13,
12: 14,
13: 14,
14: 14,
15: 14,
16: 15,
17: 15,
18: 15,
19: 15},
'col_4': {0: 'apple',
1: 'apple',
2: 'apple',
3: 'apple',
4: 'apple',
5: 'apple',
6: 'apple',
7: 'apple',
8: 'apple',
9: 'apple',
10: 'apple',
11: 'apple',
12: 'apple',
13: 'apple',
14: 'apple',
15: 'apple',
16: 'apple',
17: 'apple',
18: 'apple',
19: 'apple'},
'ID_y': {0: 1,
1: 1,
2: 3,
3: 5,
4: 1,
5: 1,
6: 3,
7: 5,
8: 1,
9: 1,
10: 3,
11: 5,
12: 1,
13: 1,
14: 3,
15: 5,
16: 1,
17: 1,
18: 3,
19: 5},
'col_1_y': {0: 8,
1: 9,
2: 10,
3: 11,
4: 8,
5: 9,
6: 10,
7: 11,
8: 8,
9: 9,
10: 10,
11: 11,
12: 8,
13: 9,
14: 10,
15: 11,
16: 8,
17: 9,
18: 10,
19: 11},
'col_2_y': {0: 12,
1: 13,
2: 15,
3: 17,
4: 12,
5: 13,
6: 15,
7: 17,
8: 12,
9: 13,
10: 15,
11: 17,
12: 12,
13: 13,
14: 15,
15: 17,
16: 12,
17: 13,
18: 15,
19: 17},
'col_3_y': {0: 12,
1: 13,
2: 14,
3: 15,
4: 12,
5: 13,
6: 14,
7: 15,
8: 12,
9: 13,
10: 14,
11: 15,
12: 12,
13: 13,
14: 14,
15: 15,
16: 12,
17: 13,
18: 14,
19: 15}}
Edit: if first row from df1 got matched with first row from df2, then the second row from df1 cannot be matched again with first row of df2 but it should be matched with the second row from df2 if there is a match.
CodePudding user response:
You can add a serial number serial for each group of same value of col_4 in each of df1 and df2. Then, merge by col_4 and this serial number serial, as follows:
We generate the serial number by .groupby() cumcount():
df1['serial'] = df1.groupby('col_4').cumcount()
df2['serial'] = df2.groupby('col_4').cumcount()
df1.merge(df2, on=['col_4', 'serial'])
Result:
ID_x col_1_x col_2_x col_3_x col_4 serial ID_y col_1_y col_2_y col_3_y
0 1 1 6 11 apple 0 1 8 12 12
1 2 2 7 12 apple 1 1 9 13 13
2 3 3 8 13 apple 2 3 10 15 14
3 5 4 9 14 apple 3 5 11 17 15
Optionally, you can further remove this serial number column serial, as follows:
df1.merge(df2, on=['col_4', 'serial']).drop('serial', axis=1)
Result:
ID_x col_1_x col_2_x col_3_x col_4 ID_y col_1_y col_2_y col_3_y
0 1 1 6 11 apple 1 8 12 12
1 2 2 7 12 apple 1 9 13 13
2 3 3 8 13 apple 3 10 15 14
3 5 4 9 14 apple 5 11 17 15
Edit
You can also simplify the codes by incorporating the generations of serial numbers into the step of .merge(), as follows: (Thanks for the suggestion by @HenryEcker)
df1.merge(df2,
left_on=['col_4', df1.groupby('col_4').cumcount()],
right_on=['col_4', df2.groupby('col_4').cumcount()]
).drop('key_1', axis=1)