I am working with a pandas dataframe and using the following crosstab formula to tabulate results:
ct = pd.crosstab(index=[df['Gender'], df['Education'],df['MaritalStatus']],
columns=df['month'], normalize='columns').round(2)
The output of the cross-tabulation:
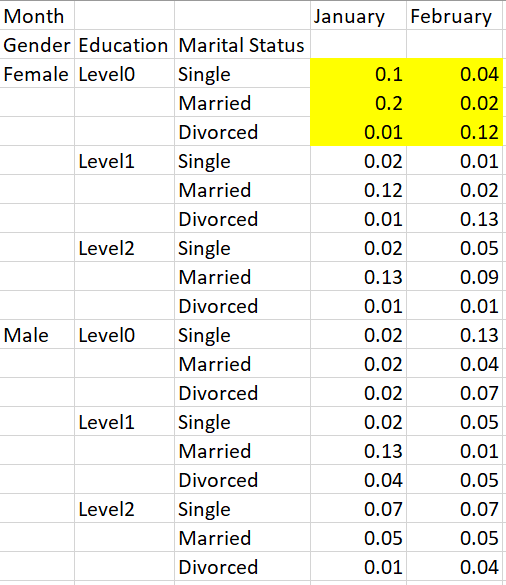
I don't want the percentages to be calculated by the whole column. Instead, for the first row for example, my desired output would be to calculate the percentage of Females who are Level0 and Single / Number of Females who are Level 0 (As highlighted in yellow).
What's the way to accomplish this?
CodePudding user response:
Use GroupBy.transform and divide original ouput (also removed normalize='columns'):
ct = pd.crosstab(index=[df['Gender'], df['Education'],df['MaritalStatus']],
columns=df['month'])
#normalize by levels Gender and Education
ct = ct.div(ct.groupby(level=['Gender','Education']).transform('sum')).round(2)