Given a dataframe I want to check whether DS1.ColA or DS1.ColB contains "Type 1" and if it does, I want to insert the corresponding DS1.Val to column Value. The same goes for DS2, check if DS2.ColA or DS2.ColB contains "Type 1" and if it does, I want to insert the corresponding DS2.Val to column Value.
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB04', 'AB05','AB06'],
'DS1.ColA': ["Type 1","Undef",np.nan,"Undef",
"Type 1", ""],
'DS1.ColB': ["N","Type 1","","",
"Y", np.nan],
'DS1.Val': [85,87,18,94,
81, 54],
'DS2.ColA': ["Type 1","Undef","Type 1","Undef",
"Type 1", ""],
'DS2.ColB': ["N","Type 2","","",
"Y", "Type 1"],
'DS2.Val': [45,98,1,45,66,36]
}
)
var_check = "Type 1"
ds1_col_check = ["DS1.ColA","DS1.ColB","DS1.Val"]
ds2_col_check = ["DS2.ColA","DS2.ColB","DS2.Val"]
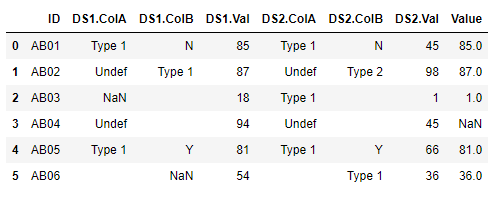
The last element of ds1_col_check and ds2_col_check is always the element to place in the new column(There could be more columns to checks in the list).The end result df should look like this. How do I achieve this in python?
CodePudding user response:
If there is multiple lists is possible create list L and for each sublist test if match condition and set value to column Value, for avoid overwrite values is use Series.fillna:
var_check = "Type 1"
ds1_col_check = ["DS1.ColA","DS1.ColB","DS1.Val"]
ds2_col_check = ["DS2.ColA","DS2.ColB","DS2.Val"]
L = [ds1_col_check, ds2_col_check]
df['Value'] = np.nan
for val in L:
df.loc[df[val[:-1]].eq(var_check).any(axis=1), 'Value'] = df['Value'].fillna(df[val[-1]])
print (df)
ID DS1.ColA DS1.ColB DS1.Val DS2.ColA DS2.ColB DS2.Val Value
0 AB01 Type 1 N 85 Type 1 N 45 85.0
1 AB02 Undef Type 1 87 Undef Type 2 98 87.0
2 AB03 NaN 18 Type 1 1 1.0
3 AB04 Undef 94 Undef 45 NaN
4 AB05 Type 1 Y 81 Type 1 Y 66 81.0
5 AB06 NaN 54 Type 1 36 36.0
Or:
var_check = "Type 1"
ds1_col_check = ["DS1.ColA","DS1.ColB","DS1.Val"]
ds2_col_check = ["DS2.ColA","DS2.ColB","DS2.Val"]
df.loc[df[ds1_col_check[:-1]].eq(var_check).any(axis=1), 'Value'] = df[ds1_col_check[-1]]
df.loc[df[ds2_col_check[:-1]].eq(var_check).any(axis=1), 'Value'] = df['Value'].fillna(df[ds2_col_check[-1]])
CodePudding user response:
pyjanitor has a case_when implementation in dev that could be helpful in this case, to abstract multiple conditions (under the hood, it uses pd.Series.mask):
# pip install git https://github.com/pyjanitor-devs/pyjanitor.git
import pandas as pd
import janitor as jn
# it has a syntax of
# condition, value,
# condition, value,
# more condition, value pairing,
# default if none of the conditions match
# column name to assign values to
# similar to a case when in SQL
df.case_when(
df['DS1.ColA'].str.contains('Type 1') | df['DS1.ColB'].str.contains('Type 1'), df['DS1.Val'],
df['DS2.ColA'].str.contains('Type 1') | df['DS2.ColB'].str.contains('Type 1'), df['DS2.Val'],
np.nan,
column_name = 'Value')
ID DS1.ColA DS1.ColB DS1.Val DS2.ColA DS2.ColB DS2.Val Value
0 AB01 Type 1 N 85 Type 1 N 45 85.0
1 AB02 Undef Type 1 87 Undef Type 2 98 87.0
2 AB03 NaN 18 Type 1 1 1.0
3 AB04 Undef 94 Undef 45 NaN
4 AB05 Type 1 Y 81 Type 1 Y 66 81.0
5 AB06 NaN 54 Type 1 36 36.0