I have a data frame with vendor, bill amount, and payment type.
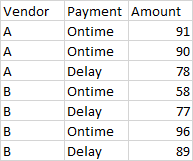
I want to add a column in which I will get sum of late payment by Vendor.
Is it be possible to write one line code to get this output?
df['Paid Late by Vendor']=
CodePudding user response:
You can use a combination of groupby.transform and bfill(), and assign back to a new column using assign:
df = df.assign(late_payments=df[df['Payment'].eq('Delay')].groupby('Vendor')['Amount'].transform('sum')).bfill()
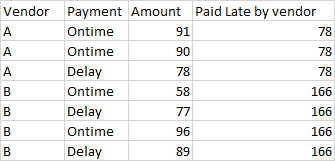
Prints:
Vendor Payment Amount late_payments
0 A Ontime 91 78.0
1 A Ontime 90 78.0
2 A Delay 78 78.0
3 B Ontime 58 166.0
4 B Delay 77 166.0
5 B Ontime 96 166.0
6 B Delay 89 166.0
CodePudding user response:
Let's define the dataframe:
data = pd.DataFrame({'Vendor':['A', 'A', 'B', 'B'],
'Payment':['Ontime', 'Delay', 'Ontime', 'Delay'],
'Paid Late by Vendor':[20, 21, 19, 18]})
to get the results you want you need to create a separate dataframe with grouped values and then combine it with the original.
Since you want a value for only late payments then you need to filter the data to-be-grouped to have only the wanted records, and group on it.
reset_index() is used to make the index a column(in this case it's the column that we grouped on; Vendor)
groupedLateData = data[data['Payment']=='Delay'].groupby('Vendor')["Paid Late by Vendor"].sum().reset_index()
Then we merge the resulting dataframe with the original on the Vendor column
pd.merge(data, groupedLateData, on='Vendor')
and this would be the result: 