I have two dataframes, one long and one wide, and I am trying to merge the two together. I have demographic information in the wide format that I need to bring into the long format for analysis. When I merge the two dataframes, the information from the wide format only populates one row and the remainder are blank.
Here is some sample data to show what I'm working with and the outcome I'm hoping for. The only problem is that the merge works in the sample data but not in my actual data.
df_long <- data.frame (id = c(123, 123, 123, 345, 345),
x = c("abc", "cgf", "add", "wer", "nko"),
y = c(234, 234, 5436, 73435, 2353))
df_wide <- data.frame(id = c(123, 345),
person = c("Mom", "Teen"))
When I use this code to merge the sample data, it results in how I want the data
df_goal <- merge(df_long, df_wide)
And when I use this code, it has the right number of variables, but 0 observations.
real_merged <- merge(real_long, real_wide)
To fix it, I add the all = T argument but I get more observations than I would expect. It looks like the merge just adds the number of observations from df_wide to df_long, but doesn't match them by the ID. I have visually confirmed that there are matching IDs, so this shouldn't happen.
My real data has over 100k rows and 150 variables. I'm not sure if that has anything to do with it so I'm just throwing it out there.
I've tried using different arguments in the merge function like all = T and also not using it, as well as the by = and by.x = but none results in what I am looking for. I've also looked into using melt(), but I can't get it to work.
Since there are no errors and it doesn't reproduce in the sample data it makes it almost impossible to troubleshoot. I'm hoping that someone out there has had a similar issue and knows the fix.
CodePudding user response:
You simply have to specify that you want to keep all data of one of your tables, not all data of both (all=TRUE keeps all data of both tables, which is the default).
df_long <- data.frame (id = c(123, 123, 123, 345, 345),
x = c("abc", "cgf", "add", "wer", "nko"),
y = c(234, 234, 5436, 73435, 2353))
df_wide <- data.frame(id = c(123, 345),
person = c("Mom", "Teen"))
df_goal <- merge(df_long, df_wide, all.x=TRUE, by="id")
The output looks as like this:
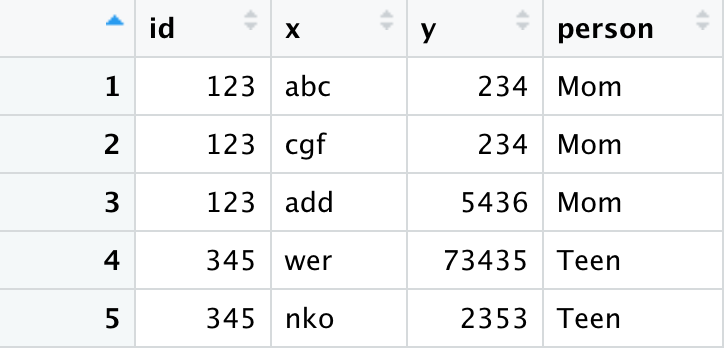
Here all.x=TRUE means that extra rows will be added to the output, one for each row in x that has no matching row in y. These rows will have NAs in those columns that are usually filled with values from y. Inversely, if they do have a match than the value of y will be used.
CodePudding user response:
Okay, I was able to figure it out. I was importing SPSS files into R and one of the dataframes had the variable labels attached which seems to be why the ID values weren't linking. I'm not sure why that was happening, but I saved the SPSS file as an Excel file and then imported that into R and the merge worked perfectly.