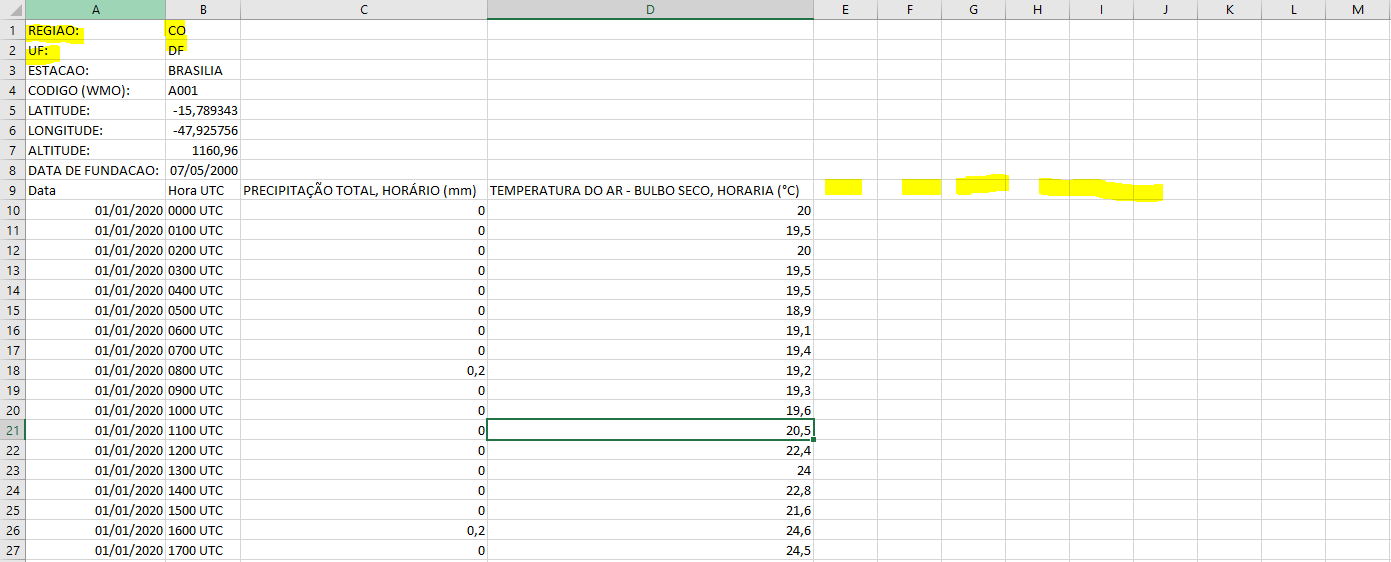
So what I need to do is create columns with the values stated on the first 9 lines... The value at cell A1, for example, should be at E9 and the value at B1 should be at E10, E11, E12, E13, ...
CodePudding user response:
Fake CSV data, stored as "foo.csv":
REG,CO
UF,DF
ESTACAO,BRASILIA
Date,Hora,PRECIP,TEMP
01/01/2020,0000 UTC,0,20
01/01/2000,0100 UTC,0,19.5
01/01/2000,0200 UTC,0,21
Reading it in, finding the "real" header row, then moving on:
alldat <- readLines("foo.csv")
alldat
# [1] "REG,CO" "UF,DF" "ESTACAO,BRASILIA" "Date,Hora,PRECIP,TEMP"
# [5] "01/01/2020,0000 UTC,0,20" "01/01/2000,0100 UTC,0,19.5" "01/01/2000,0200 UTC,0,21"
ind <- grep("Hora", alldat)
ind
# [1] 4
From here, we can determine both the header info and the rest of the data:
header <- as.data.frame(t(read.csv(text = alldat[1:(ind-1)], header = FALSE, row.names = 1L)))
header
# REG UF ESTACAO
# V2 CO DF BRASILIA
rest_of_data <- read.csv(text = alldat[ind:(length(alldat))])
rest_of_data
# Date Hora PRECIP TEMP
# 1 01/01/2020 0000 UTC 0 20.0
# 2 01/01/2000 0100 UTC 0 19.5
# 3 01/01/2000 0200 UTC 0 21.0
We can then cbind them:
rownames(header) <- NULL
cbind(rest_of_data, header)
# Date Hora PRECIP TEMP REG UF ESTACAO
# 1 01/01/2020 0000 UTC 0 20.0 CO DF BRASILIA
# 2 01/01/2000 0100 UTC 0 19.5 CO DF BRASILIA
# 3 01/01/2000 0200 UTC 0 21.0 CO DF BRASILIA
(Clearing the row names was purely to preempt a warning when cbinding, it is not strictly required.)