Summary:
What is expected token for declare spark submit (python script) in shell script with specific directory input? What punctuation should I use?
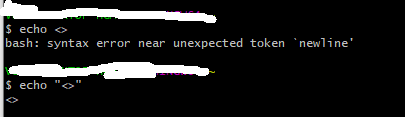
I already try < , but it doesn't work
Detail:
I try to give as much as detail possible on my case to understand my situation. My input is in
sys.argv[1] for dataset_1, dataset_2, dataset_3
sys.argv[2] for dataset_4
sys.argv[3] for dataset_5
sys.argv[4] for dataset_6
My Output
sys.argv[5]
Additional input in
sys.argv[6] for year
sys.argv[7] for month
Here is part of the script, the file name is cs_preDeploy.py
import os
import sys
#/tmp/sdsid/encrypted_dataset/ae80ead7-bcf1-43ca-a888-03f6ba48f4b9/0/dataset_1/year=2021/month=1
input_path_1 = os.path.join(sys.argv[1], 'dataset_1')
#/tmp/sdsid/encrypted_dataset/ae80ead7-bcf1-43ca-a888-03f6ba48f4b9/0/dataset_2/year=2021/month=1
input_path_2 = os.path.join(sys.argv[1], 'dataset_2')
#/tmp/sdsid/encrypted_dataset/ae80ead7-bcf1-43ca-a888-03f6ba48f4b9/0/dataset_3/year=2021/month=1
input_path_3 = os.path.join(sys.argv[1], 'dataset_3')
# /tmp/sdsid/encrypted_dataset/328b7446-1862-4489-b1b4-57fa55fe556a/0/dataset_4/year=2021/month=2
input_path_4 = os.path.join(sys.argv[2], 'dataset_4')
# /tmp/sdsid/encrypted_dataset/3119bdd9-c7a8-44c3-b3f8-e49a86261106/0/dataset_5/year=2021/month=2
input_path_5 = os.path.join(sys.argv[3], 'dataset_5')
# /tmp/sdsid/encrypted_dataset/efc84a0f-52e9-4dff-91a1-56e1d7aa02cb/0/dataset_6/year=2021/month=2
input_path_6 = os.path.join(sys.argv[4], 'dataset_6')
output_path = sys.argv[5]
#query_year = sys.argv[6]
#query_month = sys.argv[7]
#For looping year month
if len(sys.argv) > 7:
year = int(sys.argv[6]) # year
month = int(sys.argv[7]) # month
else:
month_obs = datetime.datetime.today()
month = month_obs.month
year = month_obs.year
Here's my first try
[sdsid@user algorithm]$ PYSPARK_PYTHON=/usr/bin/python3 ./bin/spark-submit \
> --master yarn \
> --deploy-mode cluster \
> --driver-memory 16g \
> --executor-memory 16g \
> --num-executors 5 \
> --executor-cores 1 \
> ./home/sdsid/algorithm/cs_preDeploy.py
The Output
-bash: ./bin/spark-submit: No such file or directory
Here's the second try, I put year parameter for sys.argv[6] is 2021 and sys.argv[7] is 7 (July)
[sdsid@user algorithm]$ nohup spark-sumbit cs_preDeploy.py </tmp/sdsid/sample_dataset/></tmp/sdsid/sample_dataset/dataset_4></tmp/sdsid/sample_dataset/dataset_5></tmp/sdsid/sample_dataset/dataset_6></tmp/sdsid/sample_output/dataset_output/> 2021 7
The error message
-bash: syntax error near unexpected token `<'
The Third Try
[sdsid@user algorithm]$ nohup spark-sumbit cs_preDeploy.py <"/tmp/sdsid/sample_dataset/"><"/tmp/sdsid/sample_dataset/dataset_4"><"/tmp/sdsid/sample_dataset/dataset_5"><"/tmp/sdsid/sample_dataset/dataset_6"><"/tmp/sdsid/sample_output/dataset_output/"> 2021 7
The error message
-bash: syntax error near unexpected token `<'
CodePudding user response:
-bash: ./bin/spark-submit: No such file or directory
a. Put here full path like /folder1/folder2/bin/spark-submit as as ./ means current directory and depending where you are now such path may not exist.b.Or add spark submit to
 "
"Please reffer the link how to submit apps to run py spark, here a lot of examples