I'm implementing a simple reverse proxy in Python3 and I need to send a response with transfer-encoding chunked mode.
I've taken my cues from this 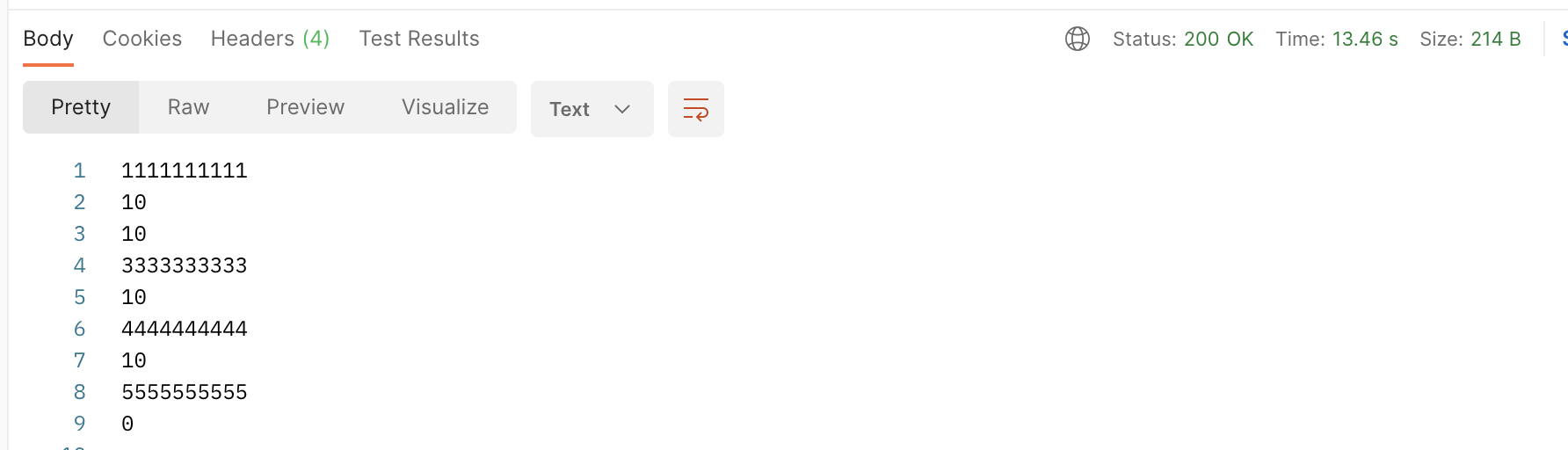
But if I use this length instead:
# writing the same 5 chunks of 9 characters
for i in range(5):
text = str(i 1) * 9 # concatenate 9 chars
chunk = '{0:d}\r\n'.format(len(text)) text '\r\n'
self.wfile.write(chunk.encode(encoding='utf-8'))
# writing close sequence
close_chunk = '0\r\n\r\n'
self.wfile.write(close_chunk.encode(encoding='utf-8'))
The communication ends correctly (after 6ms all the 5 chunks are interpreted correctly)

Some version informations:
HTTP Client: Postman 8.10
(venv) manuel@MBP ReverseProxy % python -V
Python 3.9.2
(venv) manuel@MBP ReverseProxy % pip freeze
certifi==2021.10.8
charset-normalizer==2.0.6
idna==3.2
requests==2.26.0
urllib3==1.26.7
Thanks in advance for any hints!
CodePudding user response:
I post the solution (thanks to Martin Panter from bugs.python.org) in case anyone else will have the same problem in the future.
The behaviour was caused by the chunk size part, that must be in hex format, not decimal.
Unfortunately from the Mozilla docs the format was not specified and the example used only length < 10. A formal definition is found here
In conclusion, the working version is the following (using {0:x} instead of {0:d})
# writing the same 5 chunks of 9 characters
for i in range(5):
text = str(i 1) * 9 # concatenate 9 chars
chunk = '{0:x}\r\n'.format(len(text)) text '\r\n'
self.wfile.write(chunk.encode(encoding='utf-8'))
# writing close sequence
close_chunk = '0\r\n\r\n'
self.wfile.write(close_chunk.encode(encoding='utf-8'))