I want to filter rows that are in df_1 that match the following two condition
Row from
df_1should not be indf_2OR
If row from
df_1is indf_2then it must have a valueYesindf_2
Code I tried, that does not work
import pandas as pd
df_1 = pd.DataFrame({'a': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]})
df_2 = pd.DataFrame({'a': [2, 4, 6, 8, 10], 'b': ['Yes', 'No', 'Yes', 'No', 'No']})
df = df_1[(~df_1.a.isin(df_2.a)) | (df_2.b=='Yes')]
Output
a
0 1
2 3
4 5
6 7
8 9
Expected Output
a
0 1
1 2
2 3
3 6
4 5
6 7
8 9
Explanation
Rows 1, 3, 5, 7, 9 are not in df_2 so they are part of the output
Rows 2 and 6 are in df_2 but the have column b as Yes so they are part of the output
CodePudding user response:
I think you can create two frames and concat it as below.
import pandas as pd
df_1 = pd.DataFrame({'a': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]})
df_2 = pd.DataFrame({'a': [2, 4, 6, 8, 10], 'b': ['Yes', 'No', 'Yes', 'No', 'No']})
df = [df_1[(~df_1.a.isin(df_2.a))]['a'],df_2[df_2.b=='Yes']['a']]
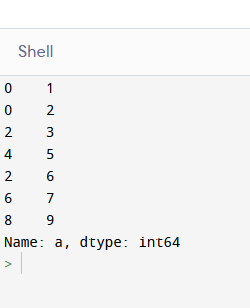
result = pd.concat(df).sort_values()
print(result)
output
CodePudding user response:
The problem in your calculation stems from the fact that df_1 and df_2 are not the same size and logical operators between their
columns does not make sense. If you map your values in df_1 to Yes, No or NaN using df_2 then you will have equal length columns that can be compared
df_1[(~df_1["a"].isin(df_2["a"])) | (df_1["a"].map(df_2.set_index("a")["b"]) == "Yes")]
CodePudding user response:
You can use:
df = df_1.merge(df_2, how='left', on='a')
print(df[df.b.isin(['Yes', np.nan])][['a']])
OUTPUT
a
0 1
1 2
2 3
4 5
5 6
6 7
8 9
CodePudding user response:
This won't be the fastest solution but the steps should be easy enough for you to follow. When the two dataframes are merged using a union, NaN values are added in place of missing data. Afterwards you want to retain those rows so you only need to remove those which have the value No.
import pandas as pd
df_1 = pd.DataFrame({'a': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]})
df_2 = pd.DataFrame({'a': [2, 4, 6, 8, 10], 'b': ['Yes', 'No', 'Yes', 'No', 'No']})
# Merge the dataframes using a union
df = df_1.merge(df_2, how='outer', on='a')
# Drop the rows where 'b' == 'No'
df.drop(df[df['b']=='No'].index, inplace=True)
# Drop column 'b'
df.drop('b', axis=1, inplace=True)