am trying to web scrap the information using selenium ,code is working for single item, but when am passing the list am getting the below output,
Actual Output

Expected output
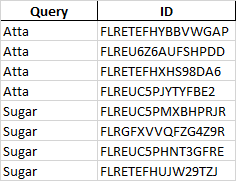
term=["Atta","Sugar"]
def get_link(term,page):
for term in term:
pin(Pincode)
grocery="https://www.flipkart.com/search?q={}&otracker=search&otracker1=search&marketplace=GROCERY&as-show=on&as=off"
term = term.replace(' ', ' ')
stem = grocery.format(term)
url_template = stem '&as-pos=1&as-type=HISTORY&as-backfill=on&page='
next=url_template str(page)
#print(next)
return next
def PID():
for page in range(1,5):
path=get_link(term,page)
driver.get(path)
id=driver.find_elements_by_xpath('//div[@data-id]')
for i in id:
results=i.get_attribute('data-id')
#print(results)
PIDs.append(results)
Search_Term.append(term)
PID()
ID={'Query':Search_Term,'PID_s':PIDs}
Output=pd.DataFrame(ID)
print(Output)
CodePudding user response:
May be it would be better to put the for loop for term inside the PID function. Try like below once:
terms = ["Atta", "Sugar"]
def get_link(term, page):
# Not sure what pin(Pincode) line is doing
grocery = "https://www.flipkart.com/search?q={}&otracker=search&otracker1=search&marketplace=GROCERY&as-show=on&as=off"
term = term.replace(' ', ' ')
#print(term)
stem = grocery.format(term)
url_template = stem '&as-pos=1&as-type=HISTORY&as-backfill=on&page='
next = url_template str(page)
# print(next)
return next
def PID():
for term in terms:
for page in range(1, 5):
path = get_link(term, page)
driver.get(path)
id = driver.find_elements_by_xpath('//div[@data-id]')
for i in id:
results = i.get_attribute('data-id')
print(f"{term}:{results}")
# PIDs.append(results)
# Search_Term.append(term)
PID()
Atta:FLRFDPRFNGYJ95KD
Atta:FLRETEFHENWKNJQE
...
Sugar:SUGG4SFGSP6TCQ48
Sugar:SUGEUD25B6YCCNGM
...