I have a dataframe looks like this:
date id value type
2021-01-02 123123 0.3 apple
2021-01-02 123123 2.05 banana
2021-01-02 456456 2.01819 apple
2021-01-02 456456 606800000 banana
2021-01-02 567567 2.2 apple
2021-01-02 891891 2475368 banana
........
Where the datatype for column value is decimal.Decimal.
My expected result looks like this:
date id apple banana
2021-01-02 123123 0.3 2.05
2021-01-02 456456 2.01819 606800000
2021-01-02 567567 2.2 NaN
2021-01-02 891891 Nan 2475368
I tried to use pandas.pivot_table:
pivot_df = pd.pivot_table(df,
values='value',
index=['date', 'id'],
columns='type').reset_index().rename_axis(None, axis=1)
This gave me result (with only the first two columns):
date id
2021-01-02 123123
2021-01-02 456456
2021-01-02 567567
2021-01-02 891891
...
Does anyone what's going on here? Why I only got two columns? Thanks.
Update:
I saw the comments and answers saying can't reproduce the dataframe with two columns, that's so weird, is it because I'm using an older verion of pandas? I still only got two columns...I'm using Python3.8 pandas==1.3.0
Below is my result:
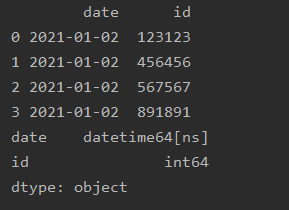
I managed to get the expected result by using pandas 1.3.3.
CodePudding user response:
Your code works for me, I can't reproduce your issue.
My setup:
import pandas as pd
from pandas import Timestamp
from decimal import Decimal
data = {'date': [Timestamp('2021-01-02 00:00:00'),
Timestamp('2021-01-02 00:00:00'),
Timestamp('2021-01-02 00:00:00'),
Timestamp('2021-01-02 00:00:00'),
Timestamp('2021-01-02 00:00:00'),
Timestamp('2021-01-02 00:00:00')],
'id': [123123, 123123, 456456, 456456, 567567, 891891],
'value': [Decimal('0.299999999999999988897769753748434595763683319091796875'),
Decimal('2.04999999999999982236431605997495353221893310546875'),
Decimal('2.018190000000000150492951433989219367504119873046875'),
Decimal('606800000'),
Decimal('2.20000000000000017763568394002504646778106689453125'),
Decimal('2475368')],
'type': ['apple', 'apple', 'apple', 'banana', 'apple', 'banana']}
df = pd.DataFrame(data)
Pivot:
pivot_df = pd.pivot_table(df,
values='value',
index=['date', 'id'],
columns='type').reset_index().rename_axis(None, axis=1)
Output:
>>> df
date id apple banana
0 2021-01-02 123123 1.17500 NaN
1 2021-01-02 456456 2.01819 606800000.0
2 2021-01-02 567567 2.20000 NaN
3 2021-01-02 891891 NaN 2475368.0
CodePudding user response:
I am also getting 4 columns with your code I'm running:
import pandas as pd
import sys
print(pd.__version__)
print(sys.version)
df = pd.read_csv('data.csv')
pivot_df = pd.pivot_table(df,
values='value',
index=['date', 'id'],
columns='type').reset_index().rename_axis(None, axis=1)
print(pivot_df.to_string())
Output
1.0.3
3.7.7 (default, Apr 15 2020, 05:09:04) [MSC v.1916 64 bit (AMD64)]
date id apple banana
0 2021-01-02 123123 0.30000 2.050000e 00
1 2021-01-02 456456 2.01819 6.068000e 08
2 2021-01-02 567567 2.20000 NaN
3 2021-01-02 891891 NaN 2.475368e 06