I have multivariate time series data, collected every 5 seconds for a few days.
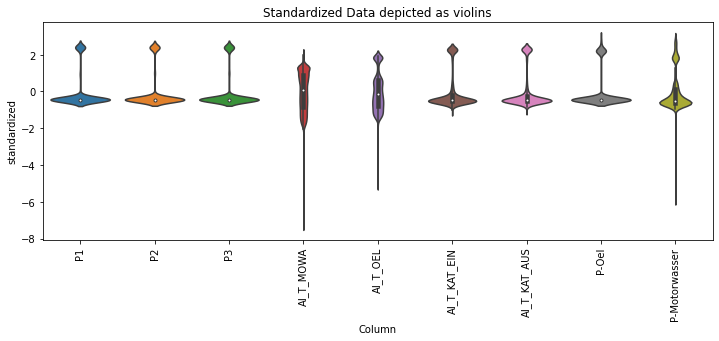
This includes columns of standardized data, which looks like below (few example values). "P1" is the label-column.
|-------|-----------------------|-----------------------|----------------------|-----------------------|-----------------------|------------------------|------------------------|----------------------|----------------------|
| | P1 | P2 | P3 | AI_T_MOWA | AI_T_OEL | AI_T_KAT_EIN | AI_T_KAT_AUS | P-Oel | P-Motorwasser |
|-------|-----------------------|-----------------------|----------------------|-----------------------|-----------------------|------------------------|------------------------|----------------------|----------------------|
| 0 | 0.8631193380009695 | 0.8964414887167506 | 0.8840858759128901 | -0.523186057460264 | -0.6599697679790338 | 0.8195843978382326 | 0.6536355179773343 | 2.0167991331023862 | 1.966765280217274 |
|-------|-----------------------|-----------------------|----------------------|-----------------------|-----------------------|------------------------|------------------------|----------------------|----------------------|
| 1 | 2.375731412346451 | 2.416190921505275 | 2.3921080971495456 | 1.2838015319452019 | 0.6783070711474897 | 2.204838829646018 | 2.250184559609546 | 2.752702514412287 | 2.7863834647854797 |
|-------|-----------------------|-----------------------|----------------------|-----------------------|-----------------------|------------------------|------------------------|----------------------|----------------------|
| 2 | 2.375731412346451 | 2.416190921505275 | 2.3921080971495456 | 1.2838015319452019 | 1.2914092683827934 | 2.2484584825559955 | 2.2968465552769324 | 2.4571347629025726 | 2.743245665597679 |
|-------|-----------------------|-----------------------|----------------------|-----------------------|-----------------------|------------------------|------------------------|----------------------|----------------------|
| 3 | 2.3933199248388406 | 2.416190921505275 | 2.3753522946913606 | 1.2838015319452019 | 1.5485166414169536 | 2.2557284247076588 | 2.3039344533529906 | 2.31839887954087 | 2.7863834647854797 |
|-------|-----------------------|-----------------------|----------------------|-----------------------|-----------------------|------------------------|------------------------|----------------------|----------------------|
Corresponding graphs of the standardized data show nothing out of the ordinary.
I have split this data into train, validation and test sets, so that my training data is the first 70% of overall data, the validation are the next 20% and the test are the last 10%.
train_df_st = df[0:int(self._n*0.7)]
val_df_st = df[int(self._n*0.7):int(self._n*0.9)]
test_df_st = df[int(self._n*0.9):]
I then generate windows through the WindowGenerator class from tensorflows tutorial like 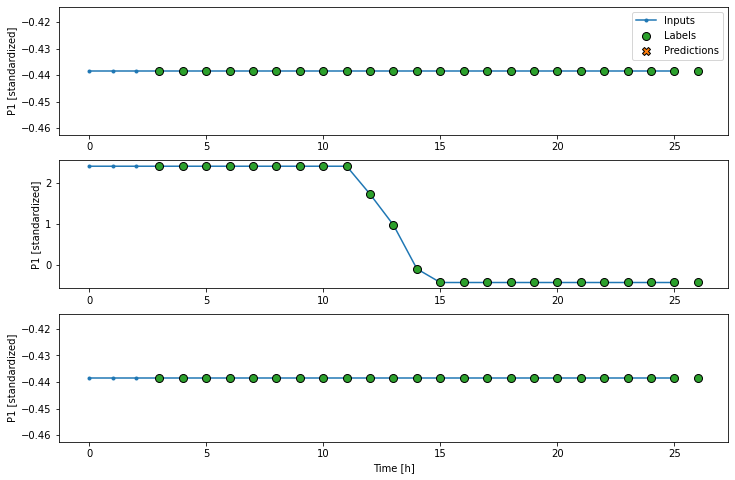
I have tried implementing yet another model (LSTM) with slightly different windows, but a similar approach, but I get the same NaN's, so I believe it is not my models problem, but something in my data?.
CodePudding user response:
Turns out my standarization of the data was faulty, normalizing it, I get actual values instead of NaN.