I am trying to attempt web-scraping a real estate website using Scrapy and PyCharm, and failing miserably.
Desired Results:
- Scrape 1 base URL (

Current Scrapy Code: This is what I have so far. When I use the scrapy crawl unegui_apts I cannot seem to get the results I want. I'm so lost.
# -*- coding: utf-8 -*- # Import library import scrapy from scrapy.crawler import CrawlerProcess from scrapy import Request # Create Spider class class UneguiApartments(scrapy.Spider): name = 'unegui_apts' allowed_domains = ['www.unegui.mn'] custom_settings = {'FEEDS': {'results1.csv': {'format': 'csv'}}} start_urls = [ 'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/1-r/,' 'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/2-r/' ] headers = { 'user-agent': "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36" } def parse(self, response): self.logger.debug('callback "parse": got response %r' % response) cards = response.xpath('//div[@]') for card in cards: name = card.xpath('.//meta[@itemprop="name"]/text()').extract_first() price = card.xpath('.//meta[@itemprop="price"]/text()').extract_first() city = card.xpath('.//meta[@itemprop="areaServed"]/text()').extract_first() date = card.xpath('.//*[@]/text()').extract_first().strip().split(', ')[0] request = Request(link, callback=self.parse_details, meta={'name': name, 'price': price, 'city': city, 'date': date}) yield request next_url = response.xpath('//li[@]/a/@href').get() if next_url: # go to next page until no more pages yield response.follow(next_url, callback=self.parse) # main driver if __name__ == "__main__": process = CrawlerProcess() process.crawl(UneguiApartments) process.start()CodePudding user response:
Your code has a number of issues:
- The
start_urlslist contains invalid links - You defined your
user_agentstring in theheadersdictionary but you are not using it when yieldingrequests - Your xpath selectors are incorrect
- The
next_urlis incorrect hence does not yield new requests to the next pages
I have updated your code to fix the issues above as follows:
import scrapy from scrapy.crawler import CrawlerProcess # Create Spider class class UneguiApartments(scrapy.Spider): name = 'unegui_apts' allowed_domains = ['www.unegui.mn'] custom_settings = {'FEEDS': {'results1.csv': {'format': 'csv'}}, 'USER_AGENT': "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"} start_urls = [ 'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/' ] def parse(self, response): cards = response.xpath( '//li[contains(@class,"announcement-container")]') for card in cards: name = card.xpath(".//a[@itemprop='name']/@content").extract_first() price = card.xpath(".//*[@itemprop='price']/@content").extract_first() date = card.xpath("normalize-space(.//div[contains(@class,'announcement-block__date')]/text())").extract_first() city = card.xpath(".//*[@itemprop='areaServed']/@content").extract_first() yield {'name': name, 'price': price, 'city': city, 'date': date} next_url = response.xpath("//a[contains(@class,'red')]/parent::li/following-sibling::li/a/@href").extract_first() if next_url: # go to next page until no more pages yield response.follow(next_url, callback=self.parse) # main driver if __name__ == "__main__": process = CrawlerProcess() process.crawl(UneguiApartments) process.start()You run the above spider by executing the command
python <filename.py>since you are running a standalone script and not a full blown project.Sample csv results are as shown in the image below. You will need to clean up the data using
pipelinesand the scrapyitemclass. See the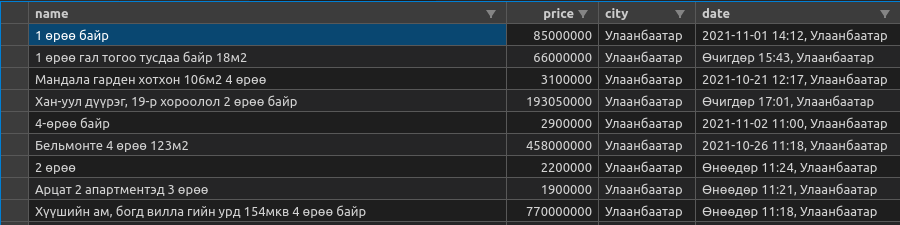
- The