This question is similiar to 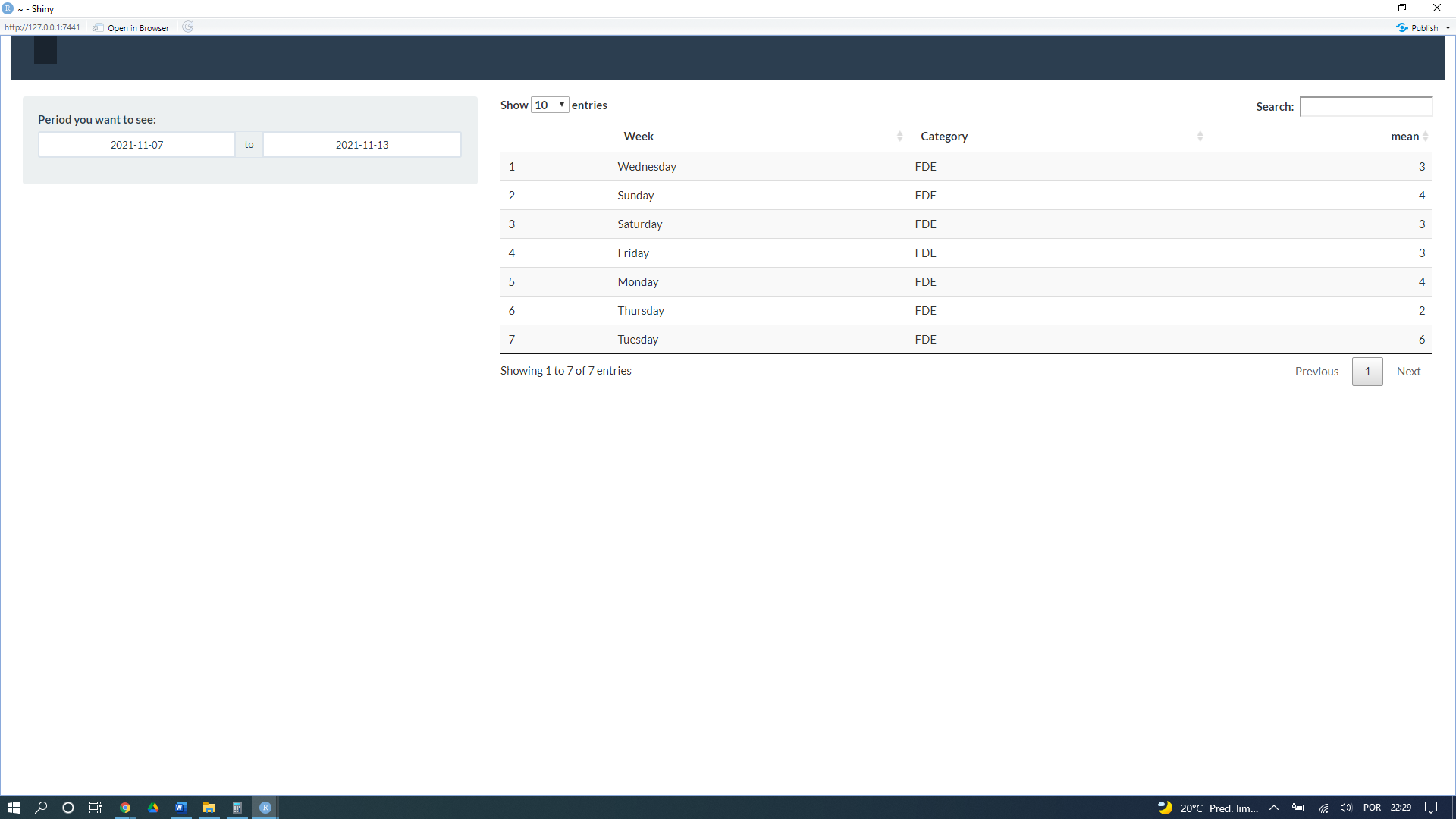
CodePudding user response:
When you use match, you need to either (a) give it every possible distinct value, or (b) know that a returned NA is inherently what you want/need.
In the use of
arrange(match(WeekP, weekdays(input$daterange1)))
it is matching the values of several values again the values of just two things. You aren't telling it to sort based on a full sequence of things, you are telling R "please sort this vector of things based on two strings". You are assuming that R will infer what those two strings are, and how to project that inference onto the rest of your data.
In this case, since weekdays(input$..) only includes two days of the week, everything else in your match(.) will be NA, which is obviously broken. Had you further debugged your code and looked at the output of just match(.., weekdays(..)) (assign to some column), you would see
left_join(meanTest, wk_port2eng, by = c("Week" = "WeekE")) %>%
select(-WeekP) %>%
mutate(sortcol = match(Week, weekdays(input$daterange1)))
# # A tibble: 7 x 4
# Week Category mean sortcol
# <chr> <chr> <dbl> <int>
# 1 Friday FDE 3 NA
# 2 Monday FDE 4 NA
# 3 Saturday FDE 3 2
# 4 Sunday FDE 4 1
# 5 Thursday FDE 2 NA
# 6 Tuesday FDE 6 NA
# 7 Wednesday FDE 3 NA
for which arrange will not magically infer your needs.
Use seq on your input range.
left_join(meanTest, wk_port2eng, by = c("Week" = "WeekE")) %>%
select(-WeekP) %>%
mutate(sortcol = match(Week, unique(weekdays(seq(input$daterange1[1], input$daterange1[2], by = "day")))))
# # A tibble: 7 x 4
# Week Category mean sortcol
# <chr> <chr> <dbl> <int>
# 1 Friday FDE 3 6
# 2 Monday FDE 4 2
# 3 Saturday FDE 3 7
# 4 Sunday FDE 4 1
# 5 Thursday FDE 2 5
# 6 Tuesday FDE 6 3
# 7 Wednesday FDE 3 4
So that one reactive block should be:
data_subset <- reactive({
req(input$daterange1)
req(input$daterange1[1] <= input$daterange1[2])
days <- seq(input$daterange1[1], input$daterange1[2], by = 'day')
Test1 <- dplyr::filter(data(), date1 %in% days)
weeks_inp <- unique(weekdays(days))
# wk <- wk_port2eng[wk_port2eng$WeekP %in% weeks_inp,] ### if weekday is in Portuguese in your notebook
wk <- wk_port2eng[wk_port2eng$WeekE %in% weeks_inp,] ### if weekday is in English in your notebook
weeks_ine <- wk$WeekE
meanTest1 <- data() %>%
group_by(Week = tools::toTitleCase(Week), Category) %>%
summarise(mean = mean(time, na.rm = TRUE), .groups = 'drop')
meanTest <- meanTest1[meanTest1$Week %in% as.character(weeks_ine),]
left_join(meanTest, wk_port2eng, by = c("Week" = "WeekE")) %>%
select(-WeekP) %>%
arrange(match(Week, unique(weekdays(seq(input$daterange1[1], input$daterange1[2], by = "day")))))
})
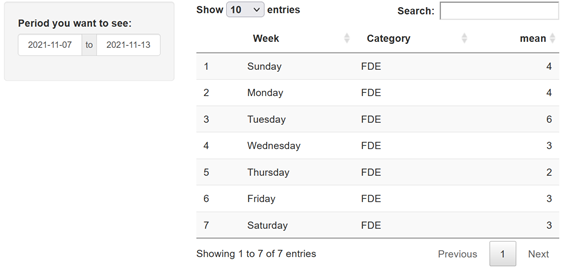
Producing:
BTW, this works fine as long as you are always summarizing by day-of-week, in which case weekdays(.) should always return a unique vector.