I'm using selenium to automaticlly download several images from google images, cause all the other solutions previously made i found on internet were too slow or weren't working, but now i need the extract the source of the image, but when i try using element.get_attribute('src') it returns the base64 of the image,even tought when i search for the xpath on the chrome devtools the src attribute of the tag it's actually a url
Code trials:
for i in range(n):
element = self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div/a/img')))
src = element.get_attribute('src')
print(element)
self.download_file(src,keyword)
EDIT:
I actually tried what some of you said and instead of downloading the image, i converted the base 64 into a image and saved it, which was amazingly faster than saving using requests and the URL, but guess it was more a problem with the Google script than with my code, cause sometimes my code broke cause src actually returned a URL, in the end, i had to make a two different functions, one if src returned a url and other if returned base64
CodePudding user response:
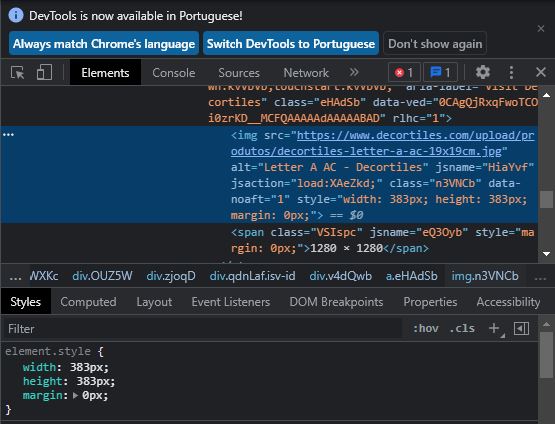
To print the value of the src attribute you need to induce WebDriverWait for the visibility_of_element_located() and you can use either of the following Locator Strategies:
Using
CSS_SELECTOR:print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "img[alt='Letter A AC - Decortiles'][src]"))).get_attribute("src"))Using
XPATH:print(WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//img[@alt='Letter A AC - Decortiles' and @src]"))).get_attribute("src"))Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC