With some df tab1 that gives summary output like below
summary(tab1)
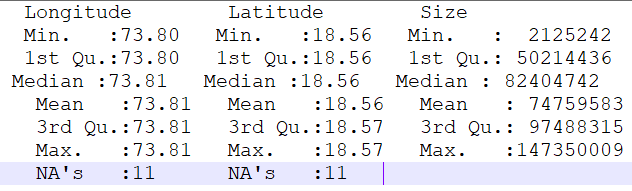
I need to extract a table out of this like below
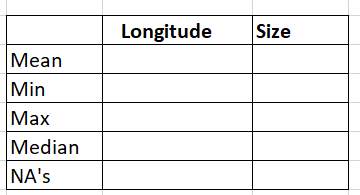
What is the right way to go about extracting data for the above table ? Looking for a solution that can use R's summary object or equivalent. Eventually I will use kabble to pretty print it.
CodePudding user response:
We could combine apply with kable_styling from kableExtra package:
library(dplyr)
library(kableExtra)
#example data
df <- mtcars %>%
select(1:3)
as.data.frame(apply(df,2,summary)) %>%
kbl() %>%
kable_styling()
CodePudding user response:
Here is another tidyverse approach. Just select the columns you want and iterate over them one at a time. This gives you a list of them that you can then join together.
library(dplyr)
library(purrr)
library(tibble)
# add in a NA value
mtcars2 <- mtcars
mtcars2[5, "wt"] <- NA
# select variables of interest
# iterate over each column to create a data frame of the summary statistics
# move through the list joining the results together
# iterate through each joined column, replacing NA with 0
summary_vars <- mtcars2 %>%
select(wt, hp) %>%
imap(~ enframe(c(summary(.x)), name = "Metric", value = .y)) %>%
reduce(full_join, by = "Metric") %>%
modify_if(is.numeric, replace_na, 0) %>%
filter(Metric %in% c("Mean", "Min.", "Max.", "Median", "NA's"))
summary_vars
# # A tibble: 7 x 3
# Metric wt hp
# <chr> <dbl> <dbl>
# 1 Min. 1.51 52
# 2 Median 3.22 123
# 3 Mean 3.21 147.
# 4 Max. 5.42 335
# 5 NA's 1 0
You can now use this summary_vars with kable().
CodePudding user response:
I think that this will give you what you want:
df <- data.frame(
a = c(rnorm(100), NA),
b = rnorm(101),
c = rnorm(101)
)
sumtab <- summary(df)
rownames(sumtab) <- names(summary(df$a))
sumtab <- sumtab[c("Mean", "Min.", "Max.", "Median", "NA's"),]
sumtab[5,][is.na(sumtab[5,])] <- 0
knitr::kable(gsub("^. \\:", "", sumtab))
| | a | b | c |
|:------|:-------|:--------|:-------|
|Mean |0.1033 |-0.03059 |-0.1172 |
|Min. |-2.0331 |-2.63760 |-1.9736 |
|Max. |1.9081 |1.93582 |2.1688 |
|Median |0.2622 |0.05986 |-0.1869 |
|NA's |1 |0 |0 |
Alternatively, you could just select the rows that you want from the summary table when you initially calculate the summary and use your preferred names:
sumtab <- summary(df)[c(4, 1, 6, 3, 7),]
rownames(sumtab) <- c("Mean", "Min", "Max", "Median", "NA")
sumtab["NA", ][is.na(sumtab["NA", ])] <- 0
knitr::kable(gsub("^. \\:", "", sumtab))
| | a | b | c |
|:------|:--------|:-------|:--------|
|Mean |-0.06337 |0.1074 |-0.00909 |
|Min |-2.27831 |-1.9913 |-2.01234 |
|Max |2.09241 |2.2401 |2.58487 |
|Median |-0.08660 |0.2212 |0.01049 |
|NA |1 |0 |0 |
CodePudding user response:
# summary of numeric (including factor class) columns of a data frame
my_summ <- function(df) {
df_nonchar <- df[, !sapply(df, typeof) %in% "character"]
summ <- data.frame(summary(df_nonchar), row.names = NULL)
# test for empty columns usually the 1st column is empty as a result of class
# (summary obj) which is "table" to data.frame coercion.
empty <- sapply(summ, function(x) all(x == ""))
summ <- summ[, !empty]
summ <- setNames(summ, c("var_name", "stats"))
summ <- summ[which(!is.na(summ$stats)), ]
# just in case if there are multiple :'s, we need to split only at the first match
summ$stats <- sub(":", "-;-", summ$stats)
summ <- data.frame(summ[1], do.call(rbind, strsplit(summ$stats, "-;-")))
names(summ)[-1] <- c("stats", "value")
# pivot into wide form, using 'stats' column as a key.
summ <- reshape(summ,
direction = "wide",
idvar = "var_name",
timevar = "stats",
v.names = "value"
)
var_nms <- strsplit(colnames(summ)[-1], "value\\.")
var_nms <- vapply(var_nms, function(x) x[[2]], NA_character_)
var_nms <- gsub("\\s $", "", var_nms) # remove white spaces
names(summ)[-1] <- var_nms
rownames(summ) <- NULL
# remove white spaces
summ <- as.data.frame(sapply(summ, function(x) gsub("\\s $", "", x)))
# when vars in the dataset contain NAs, we may have two additional columns in
# summary call
nas <- "NA's" %in% colnames(summ)
if (any(nas)) {
colnames(summ)[colnames(summ) == "NA's"] <- "missing"
}
summ
}
my_summ(mtcars[, 1:5])
var_name Min. 1st Qu. Median Mean 3rd Qu. Max.
1 mpg 10.40 15.43 19.20 20.09 22.80 33.90
2 cyl 4.000 4.000 6.000 6.188 8.000 8.000
3 disp 71.1 120.8 196.3 230.7 326.0 472.0
4 hp 52.0 96.5 123.0 146.7 180.0 335.0
5 drat 2.760 3.080 3.695 3.597 3.920 4.930
# transpose of that would put stats(summaries) on rows and vars on columns
t(my_summ(mtcars[, 1:5]))
[,1] [,2] [,3] [,4] [,5]
var_name " mpg" " cyl" " disp" " hp" " drat"
Min. "10.40" "4.000" " 71.1" " 52.0" "2.760"
1st Qu. "15.43" "4.000" "120.8" " 96.5" "3.080"
Median "19.20" "6.000" "196.3" "123.0" "3.695"
Mean "20.09" "6.188" "230.7" "146.7" "3.597"
3rd Qu. "22.80" "8.000" "326.0" "180.0" "3.920"
Max. "33.90" "8.000" "472.0" "335.0" "4.930"
CodePudding user response:
There is a nice package for it called vtable
df <- data.frame(a = c(rnorm(100), NA), b = rnorm(101), c = rnorm(101))
library(vtable)
# return will return the data as data.frame but look at other options as well
sumtable(df, out = "return")
# Variable N Mean Std. Dev. Min Pctl. 25 Pctl. 75 Max
# 1 a 100 0.235 0.955 -1.593 -0.433 0.792 3.078
# 2 b 101 0.052 1.017 -2.542 -0.675 0.654 2.753
# 3 c 101 -0.163 1.01 -2.894 -0.832 0.497 2.326
# https://cran.r-project.org/web/packages/vtable/vignettes/sumtable.html
# Options for out:
# browser: Loads output in web browser.
# viewer: Loads output in Viewer pane (RStudio only).
# htmlreturn: Returns HTML code for output file.
# return: Returns summary table in data frame format. Depending on options, the data frame may be entirely character variables.
# csv: Returns summary table in data.frame format and, with a file option, saves that to CSV.
# kable: Returns a knitr::kable()
# latex: Returns a LaTeX table.
# latexpage: Returns an independently-buildable LaTeX document.
CodePudding user response:
A tidyverse approach:
library(tidyverse)
mtcars[4,7] <- NA
mtcars %>%
summary %>%
as.data.frame %>%
separate(Freq, into = c("name", "value"),sep = ":") %>%
mutate(across(everything(), ~ str_trim(as.character(.))),
value = parse_number(value)) %>%
pivot_wider(id_cols = "name", names_from = "Var2", values_from = "value") %>%
filter(!str_detect(name,"Qu."))
#> # A tibble: 5 × 12
#> name mpg cyl disp hp drat wt qsec vs am gear carb
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Min. 10.4 4 71.1 52 2.76 1.51 14.5 0 0 3 1
#> 2 Median 19.2 6 196. 123 3.70 3.32 17.6 0 0 4 2
#> 3 Mean 20.1 6.19 231. 147. 3.60 3.22 17.8 0.438 0.406 3.69 2.81
#> 4 Max. 33.9 8 472 335 4.93 5.42 22.9 1 1 5 8
#> 5 NA's NA NA NA NA NA NA 1 NA NA NA NA