I have a data.frame and would like to average a column where there is an NA present.
when performing the calculation I noticed that R cannot calculate the average, returning NA as a result.
OBS: I cannot remove the line with NA as it would remove other columns with values that interest me.
df1<-read.table(text="st date ph
1 01/02/2004 5
16 01/02/2004 6
2 01/02/2004 8
2 01/02/2004 8
2 01/02/2004 8
16 01/02/2004 6
1 01/02/2004 NA
1 01/02/2004 5
16 01/02/2004 NA
", sep="", header=TRUE)
df2<-df1%>%
group_by(st, date)%>%
summarise(ph=mean(ph))
View(df2)
out
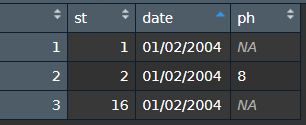
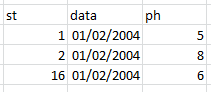
my expectation was this result:
CodePudding user response:
You need to use na.rm = TRUE:
df2<-df1%>%
group_by(st, date)%>%
summarise(ph=mean(ph, na.rm = TRUE))
df2
# A tibble: 3 x 3
# Groups: st [3]
st date ph
<int> <chr> <dbl>
1 1 01/02/2004 5
2 2 01/02/2004 8
3 16 01/02/2004 6