For example, I have a table with these values:
| ID | Date | Col1 | Col2 | Col3 | Col4 |
|---|---|---|---|---|---|
| 1 | 01/11/2021 | A | A | B | |
| 2 | 01/11/2021 | B | B |
The A and B values are dynamic, they can be other characters as well.
Now I need somehow to get to the result that id 1 has 2 occurences of A and one of B. Id 2 has 0 occurences of A and 2 occurences of B.
I'm using dynamic SQL to do this:
for v_record in table_cursor
loop
for i in 1 .. 4
loop
v_query := 'select col'||i||' from table where id = '||v_record.id;
execute immediate v_query into v_char;
if v_char = "any letter I'm checking" then
amount := amount 1;
end if;
end loop;
-- do somehting with the amount
end loop;
But there has to be a better much more efficient way to do this.
I don't have that much knowledge of plsql and I really don't know how to formulate this question in google. I've looked into pivot, but I don't think that will help me out in this case.
I'd appreciate it if someone could help me out.
CodePudding user response:
Assuming the number of columns would be fixed at four, you could use a union aggregation approach here:
WITH cte AS (
SELECT ID, Col1 AS val FROM yourTable UNION ALL
SELECT ID, Col2 FROM yourTable UNION ALL
SELECT ID, Col3 FROM yourTable UNION ALL
SELECT ID, Col4 FROM yourTable
)
SELECT
t1.ID,
t2.val,
COUNT(c.ID) AS cnt
FROM (SELECT DISTINCT ID FROM yourTable) t1
CROSS JOIN (SELECT DISTINCT val FROM cte) t2
LEFT JOIN cte c
ON c.ID = t1.ID AND
c.val = t2.val
WHERE
t2.val IS NOT NULL
GROUP BY
t1.ID,
t2.val;
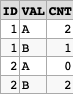
This produces: