I am doing a document reader that parse all text inside it to a google spreadsheet, this script is supposed to save time in my work, the problem is that the binary image has a lot of noise (really small points around text) that confuses pytesseract. How could i remove this noise? the code i am using to binarize the image is :
import pytesseract
import cv2
import numpy as np
import os
import re
import argparse
#binarization of images
def binarize(img):
#convert image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#apply adaptive thresholding
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 2)
#return thresholded image
return thresh
#construct argument parser
parser = argparse.ArgumentParser(description='Binarize image and parse text in image to string')
parser.add_argument('-i', '--image', help='path to image', required=True)
parser.add_argument('-o', '--output', help='path to output file', required=True)
args = parser.parse_args()
# load image
img = cv2.imread(args.image)
#binarization of image
thresh = binarize(img)
#show image
cv2.imshow('image', thresh)
cv2.waitKey(0)
cv2.destroyAllWindows()
#save image
cv2.imwrite(args.output '/imagen3.jpg', thresh)
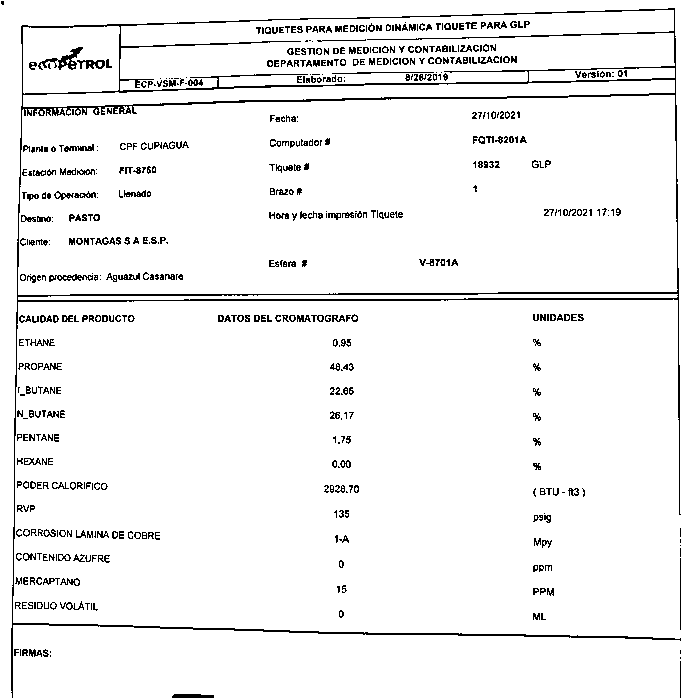
and the result image i want to clean is :
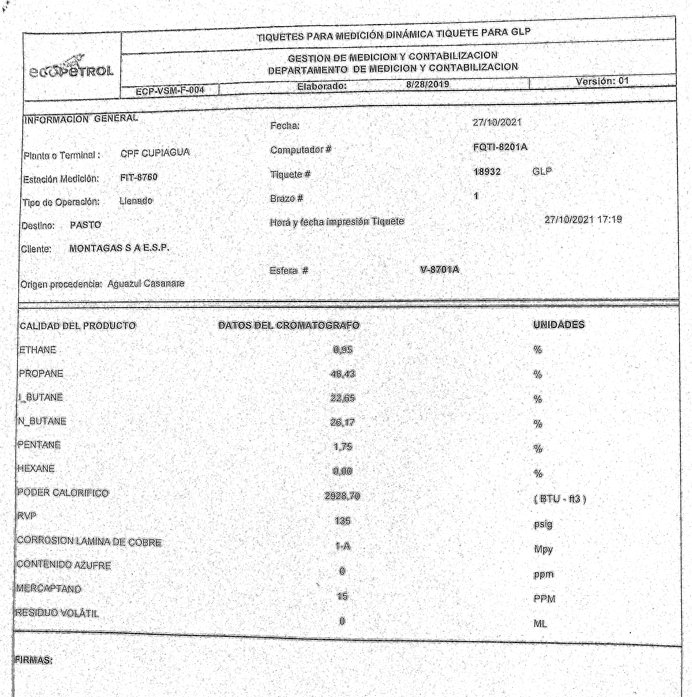
and if i apply erosion this is the result:
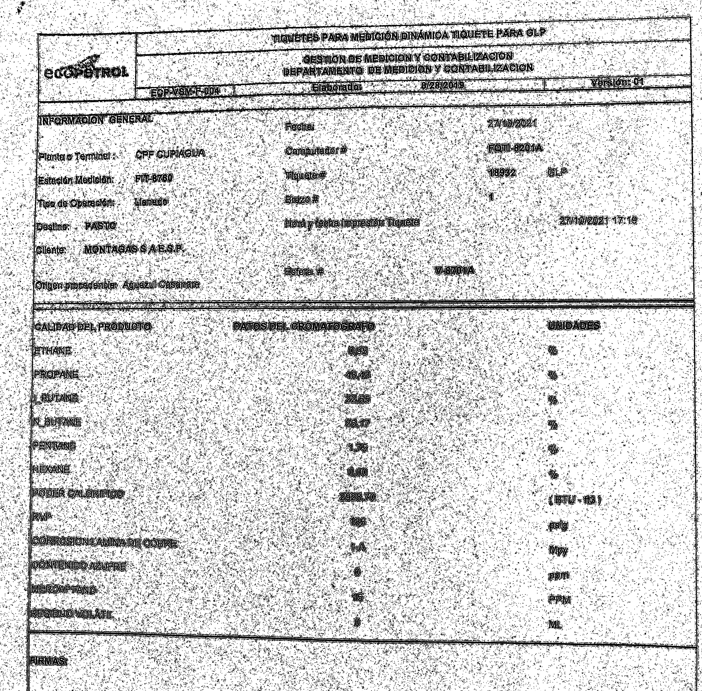
which is worst than the other
EDIT: original image is :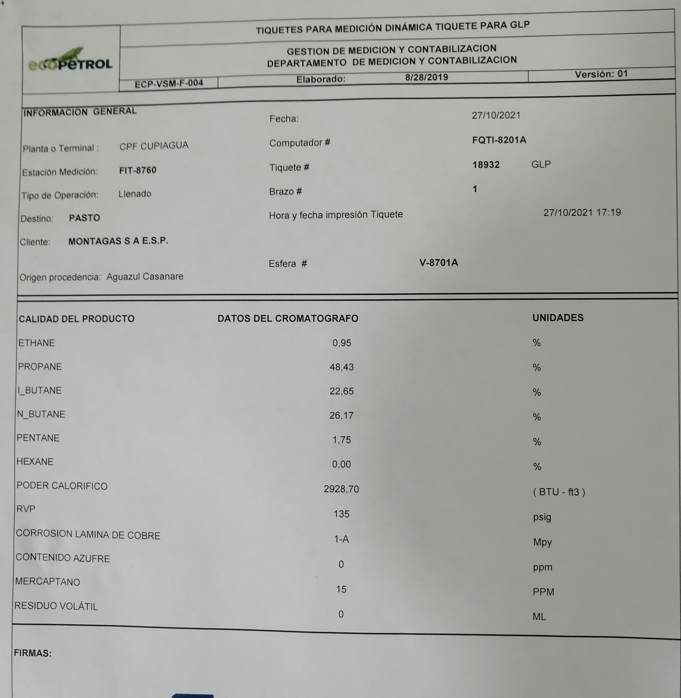
CodePudding user response:
You just need to increase your adaptive threshold arguments in Python/OpenCV.
Input:
import cv2
# read image
img = cv2.imread("petrol.png")
# convert img to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# do adaptive threshold on gray image
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 21, 25)
# write results to disk
cv2.imwrite("petrol_threshold.png", thresh)
# display it
cv2.imshow("THRESHOLD", thresh)
cv2.waitKey(0)
Results: