I am using SQL Server Management Studio 17.
I have a select statement with a group by that returns the following values. This is just a subset of 170k rows.
SELECT child, parent
FROM (SELECT child, parent
FROM table
GROUP BY child, parent) AS derivedtbl_1
ORDER BY child
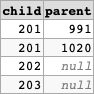
| Child | Parent |
|---|---|
| 201 | NULL |
| 201 | 991 |
| 201 | 1020 |
| 202 | NULL |
| 203 | NULL |
I am struggling to find a select statement that filters out the first row. If a child already has a parent that is NOT NULL then I want it to filter out the row with the NULL value.
I have tried to solve it with a case when having count statement. For example if a value exists more than once in the child column then I want it to filter out the row where parent is NULL but all of my code so far returns errors.
| Child | Parent |
|---|---|
| 201 | 991 |
| 201 | 1020 |
| 202 | NULL |
| 203 | NULL |
CodePudding user response:
You may use exists logic here:
SELECT child, parent
FROM yourTable t1
WHERE
Parent IS NOT NULL OR
(Parent IS NULL AND
NOT EXISTS (SELECT 1 FROM yourTable t2
WHERE t2.Child = t1.Child AND
t2.Parent IS NOT NULL));
Demo
CodePudding user response:
You can use a window function for this. It may be faster or slower than using an EXISTS self-join, you need to test
SELECT
child,
parent
FROM (
SELECT
child,
parent,
AnyParent = MAX(parent) OVER (PARTITION BY child)
FROM [table]
GROUP BY child, parent
) AS derivedtbl_1
WHERE AnyParent IS NOT NULL;
ORDER BY child