So I am doing a Time series/LSTM assignment and I have a stock dataset: 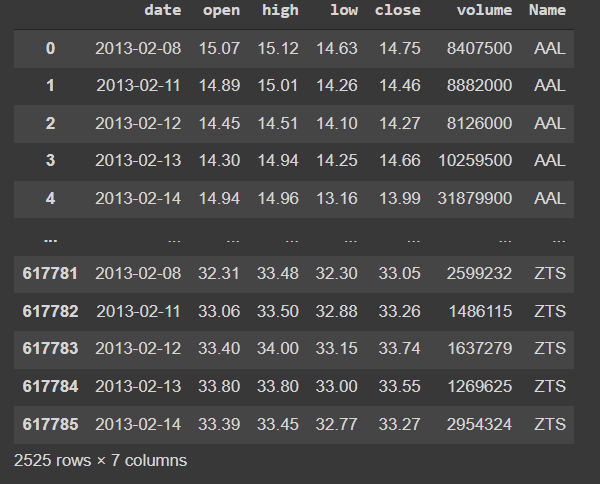
As you can see, there are different companies with different names, what I want is a dataframe for each company. Help is much appreciated
CodePudding user response:
Assume this is your dataframe:
Name price
0 aal 1
1 aal 2
2 aal 3
3 aal 4
4 aal 5
5 aal 6
6 bll 7
7 bll 8
8 bll 9
9 bll 8
10 dll 7
11 dll 56
12 dll 4
13 dll 3
14 dll 3
15 dll 5
Then do the following:
for Name, df in df.groupby('Name'):
df.to_csv("Price_{}".format(Name) ".csv", sep=";")
That'll save all sub-dataframes as csv. To view what the code does:
for Name, df in df.groupby('Name'):
print(df)
returns:
Name price
0 aal 1
1 aal 2
2 aal 3
3 aal 4
4 aal 5
5 aal 6
Name price
6 bll 7
7 bll 8
8 bll 9
9 bll 8
Name price
10 dll 7
11 dll 56
12 dll 4
13 dll 3
14 dll 3
15 dll 5
If you need to reset the index in every df, do this:
for Name, df in df.groupby('Name'):
gf = df.reset_index()
print(gf)
which gives:
index Name price
0 0 aal 1
1 1 aal 2
2 2 aal 3
3 3 aal 4
4 4 aal 5
5 5 aal 6
index Name price
0 6 bll 7
1 7 bll 8
2 8 bll 9
3 9 bll 8
index Name price
0 10 dll 7
1 11 dll 56
2 12 dll 4
3 13 dll 3
4 14 dll 3
5 15 dll 5
CodePudding user response:
This should be doable with boolean indexing:
list_of_dataframes = [
df[df.Name == name]
for name
in df.Name.unique()
]