I found a similar 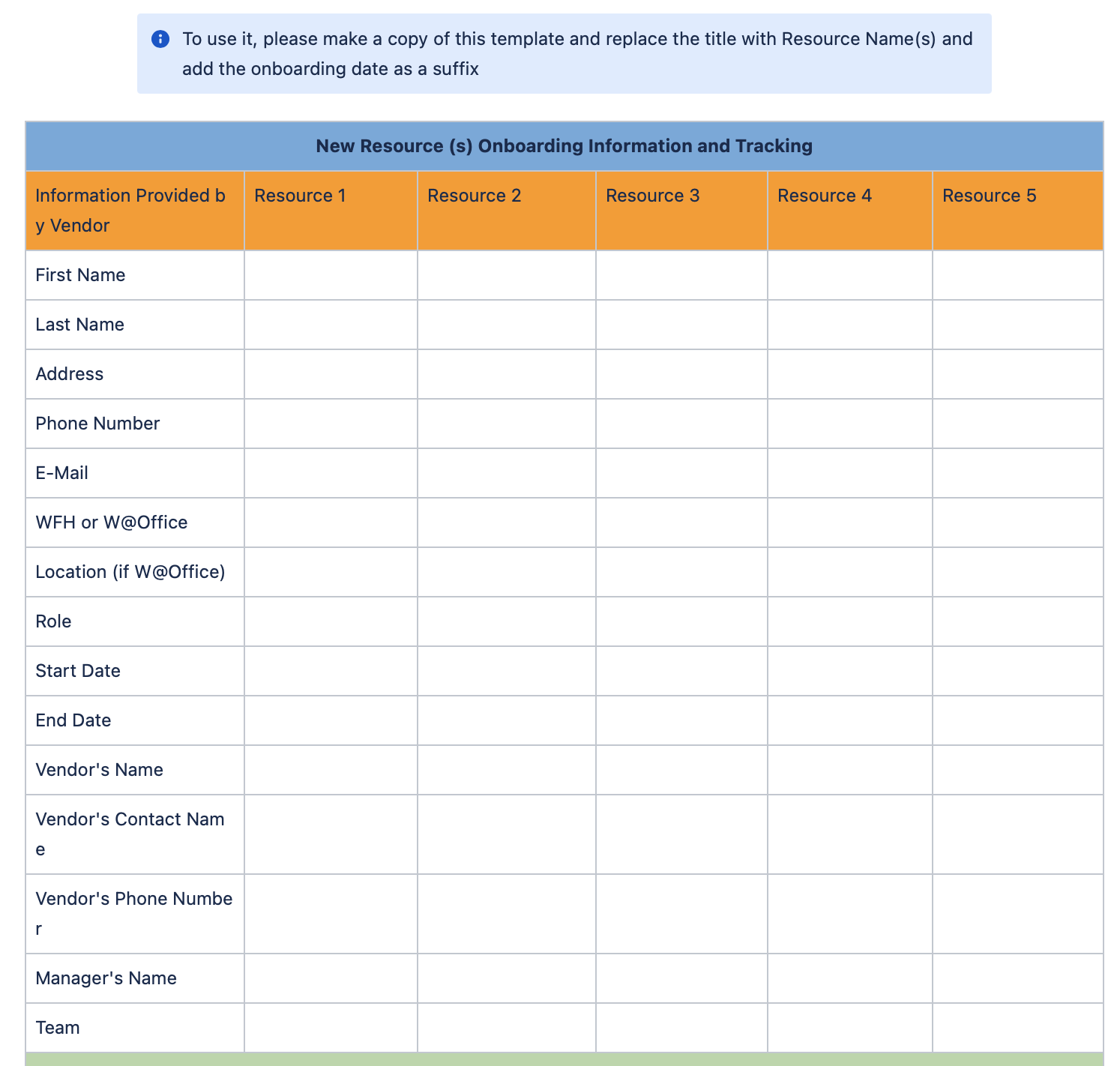
Here the following question in regard to this problem:
- Is this the best approach to get Confluence page content in order to parse it?, for example using the option:
expand=body.storageor on contrary there are better ways to get the content of Confluence page (or specific table), so it is easier to parse. - If the content obtained is the best way to do it, then is there any HTML table javascript library or tool or script to parse the table content?
CodePudding user response:
I believe your goal is as follows.
- You want to parse the HTML from the sample value (
it generates the content, but it is difficult to parse:) in your question and put them to the sheet.- You have already been able to retrieve the value from the API you want to use.
In this case, how about the following sample script? In this case, I would like to propose using Sheets API. The pasteData of Sheets API can parse the HTML table.
Sample script:
Please copy and paste the following script to the script editor of Google Spreadsheet. And, this script uses Sheets API. So 
Note:
- This sample script uses your sample value. So when the structure of the value is changed, this script might not be able to be used. So please be careful this.
- I can confirm that this script works fine when I use your sample value. So when you tested this script for your actual value, when an error occurs, please check the retrieved value again.
References:
CodePudding user response:
Here a possible solution using regular expressions to extract the information from createResponse.getContentText(). It is less generic than the solution @Tanaike provided, but it doesn't require to generate an auxiliar tab (sheet) on active Spreadsheet that needs to be removed after getting all the records:
/*
@param id {String} Confluence ID page
*/
function getOnboardRecords(id) {
const URL = https://<COMPANY>.atlassian.net/wiki/rest/api/content/%s?expand=body.storage;
const TOKEN = "Provide the token";
const USER = "Provide user name, i.e an email";
// Relevant columns to get the information
const ROW_NAMES = ["First Name", "Last Name", "Phone Number",
"E-Mail", "Role", "Start Date", "End Date", "Vendor's Name",
"Team", "New Resource ID","New Resource Company E-mail"];
function parsePhone(s) {
let ss = s.replace(/[ \(\)\- ]/g, "");
return (ss.length == 10) ? "1" ss : ss; // Adding US code
}
function parseDate(d) {
d = d.replaceAll('\\\"', "");
let dateRegEx = new RegExp('<time datetime=([0-9]{4}-[0-9]{2}-[0-9]{2}) ?/>');
return d.match(dateRegEx)[1];
}
function parseEmail(e) {
let emailRegEx1 = new RegExp("<a href=. ><u>(.*?)</u></a>"); // underline
let emailRegEx2 = new RegExp("<a href=. >(.*?)</a>"); // with mailto
let validEmailRegEx = new RegExp("^\\w ([- .']\\w )*@\\w ([-.]\\w )*\.\\w ([-.]\\w )*");
const NON_VALID_EMAIL = "The input argument: '%s' is not a valid email";
let result = e.match(emailRegEx1);
result = (result != null) ? result[1] : e.match(emailRegEx2)[1];
if(!validEmailRegEx.test(result)) throw new Error(Utilities.formatString(NON_VALID_EMAIL, result));
return result;
}
let headers = { "Authorization": "Basic " Utilities.base64Encode(USER ':' TOKEN) };
let params = {
"method": "GET",
"headers": headers,
"muteHttpExceptions": false,
"contentType": "application/json"
};
let url = Utilities.formatString(URL, id);
let createResponse = UrlFetchApp.fetch(url, params);
let content = createResponse.getContentText();
let tableRegEx = new RegExp("<table.*?>(.*?)</table>");
let tableHtml = content.match(tableRegEx)[0];
let rowRegEx = new RegExp("<tr.*?>(.*?)</tr>", "g");
let rowsResult = tableHtml.match(rowRegEx);
let colRegExp = new RegExp("<td.*?>(.*?)</td>", "g");
let values = new Map();
rowsResult.forEach(function (item) { // parsing each column of given row
item = item.replace(/<p>|<\/p>|<p ?\/>/g, "").replace(/ /g, " ");
let row = [];
[...item.matchAll(colRegExp)].forEach(item => row.push(item[1])); // Getting the group (.*?)
row = row.filter(function (item) { return item != ""; }); // Keep non empty string only
let key = ROW_NAMES.find(it => it == row[0]);
if (key) {
if (row.length > 1) {
let records = row.slice(1);
if (key == ROW_NAMES[2]) { // phone number
records.forEach(function (item, index) {
this[index] = parsePhone(item);
}, records);
}
if ((key == ROW_NAMES[5]) || (key == ROW_NAMES[6])) {
records.forEach(function (item, index) {
this[index] = parseDate(item);
}, records);
}
if ((key == ROW_NAMES[3]) || (key == ROW_NAMES[10])) {
records.forEach(function (item, index) {
this[index] = parseEmail(item);
}, records);
}
values.set(key, records);
}
}
});
return values;
}
I am parsing specific values for each row, because of the format Confluence has on my specific onboard Confluence Template.
Invoking the function with specific Confluence ID:
let onboardValues = getOnboardRecords(<ID>);
console.log(JSON.stringify([...onboardValues.entries()]))
will produce the following output for an onboarding template with two resources:
[["First Name",["FirstName1","FirstName2"]],["Last Name",
["LastName1","LastName2"]],["Phone Number",["xxxxxxxxx","xxxxxxxxx"]],
["E-Mail",["[email protected]","[email protected]"]],["Role",
["Delivery Manager","Sr. Developer"]],["Start Date",
["2021-11-01","2021-11-01"]],["End Date",["2021-11-30","2021-12-31"]],
["Vendor's Name",["xxxx","xxxxx"]],["Team",["xxxxxx]],
["New Resource ID",["xxxxxx","xxxxxx"]],
["New Resource Company E-mail",["xxxx@xxxxxx.xxx","xxxxxx@xxxx.xxx"]]]