I have been given some very poorly maintained date tables to sort out, containing information about which position members of staff held at given times. In many cases, the staff are listed with overlapping positions by date (so the data implies they held two positions at one time which should be impossible). Work is being carried out to correct the data, so I can assume that later information is a correction to older information.
I would like to clean the data so as to remove the duplication in any time frame, taking the latest modified record as the "truth" over the period between the start and end dates of the position record it applies for.
I think a diagram will help, so the below shows some possible dirty data, where one employee has been given 6 positions over a period of time. Each line represents the span of a single position (for instance the employee held position #1 between the 10th and the 20th of January). The y axis represents the date modified - position #1 was modified after position #2 and so on.
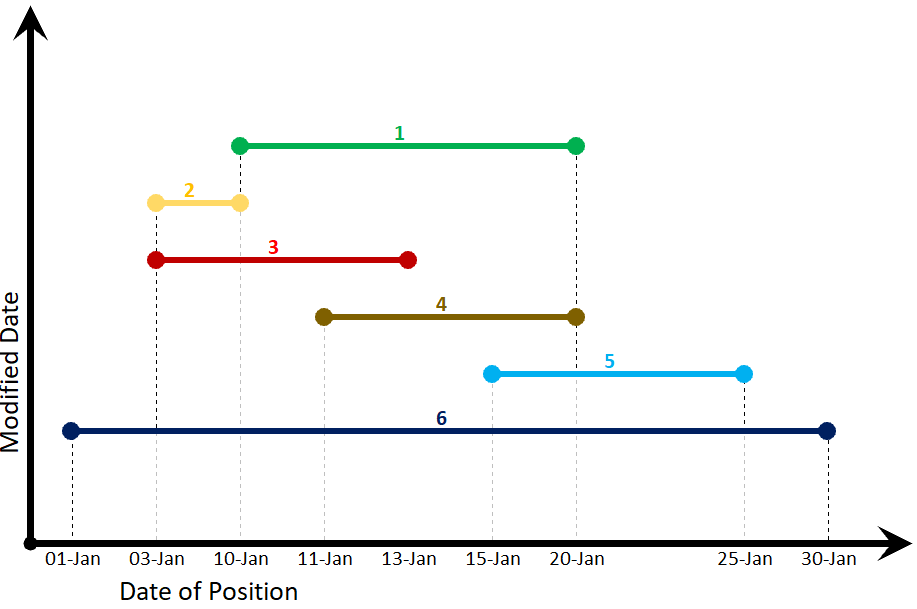
I have made a table to represent the data shown above:
DROP TABLE IF EXISTS #Test;
CREATE TABLE #Test
( Id INT IDENTITY(1,1)
,Person INT
,Job INT
,JobStart DATE
,JobEnd DATE
,Modified DATE
);
INSERT #Test
VALUES
(1,1,'2020-01-10','2020-01-20',GETDATE())
,(1,2,'2020-01-03','2020-01-10',DATEADD(DAY,-1,GETDATE()))
,(1,3,'2020-01-03','2020-01-13',DATEADD(DAY,-2,GETDATE()))
,(1,4,'2020-01-11','2020-01-20',DATEADD(DAY,-3,GETDATE()))
,(1,5,'2020-01-15','2020-01-25',DATEADD(DAY,-4,GETDATE()))
,(1,6,'2020-01-01','2020-01-30',DATEADD(DAY,-5,GETDATE()))
SELECT * FROM #Test;
DROP TABLE IF EXISTS #Test;
If you imagined that you could look "down" on the first diagram from the top of the y axis, you would see only the most recently modified position for any given time - this is what I would like to return (I don't care about the modified date in the results):
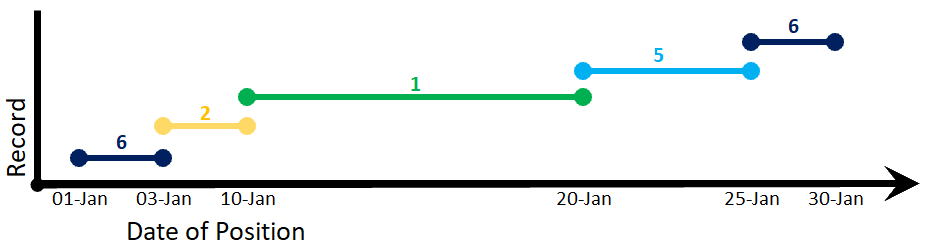
The output I, as attempted to be demonstrated above, is as follows:
| Record | Person | Job | JobStart | JobEnd |
|---|---|---|---|---|
| 1 | 1 | 6 | 2020-01-01 | 2020-01-03 |
| 2 | 1 | 2 | 2020-01-03 | 2020-01-10 |
| 3 | 1 | 1 | 2020-01-10 | 2020-01-20 |
| 6 | 1 | 5 | 2020-01-20 | 2020-01-25 |
| 7 | 1 | 6 | 2020-01-25 | 2020-01-30 |
I have attempted to modify the answers given in this question and this question, but haven't had any luck applying the modified date priority - they work to a certain extent but always seem to give confusingly incorrect results, and always return one row for each position, whereas I want to potentially create and or discard rows depending on their dates. I even tried using an extensive CASE statement, but that went about as well as you might expect.
I would welcome any suggestions of how to clean the data in this way as I have been at it all morning and spent my lunchbreak making diagrams and still no closer to a solution!
I am working in SQL Server V13.0.4
P.S. The closest I have come is using a Date Tally table that just contains a list of dates:
;WITH AllDays AS
( SELECT
Person
,Dated.[Date]
,MAX(Modified) AS LastModified
FROM #Test AS Test
INNER JOIN ListOfDates AS Dated ON Test.JobStart <= Dated.[Date]
AND Test.JobEnd >= Dated.[Date]
GROUP BY Person,[Date])
,Thing AS
(
SELECT
Test.Person
,Test.Job
,MIN([Date]) OVER (PARTITION BY Test.Job ORDER BY [Date]) AS JobStart
,MAX([Date]) OVER (PARTITION BY Test.Job ORDER BY [Date]) AS JobEnd
FROM
#Test AS Test
INNER JOIN AllDays AS Limit ON Test.Person = Limit.Person
AND Test.Modified = Limit.LastModified
)
The problem in this case is Position #6, which is still listed as only starting on the first... It feels really close, though!
I have several ways of getting to that same result, but the real sticking problem seems to be with Position #6, which needs to appear twice in the results...
;WITH Thing AS
(
SELECT
ROW_NUMBER() OVER (PARTITION BY T1.Person, [Date] ORDER BY [Modified] DESC) AS MY_Rank
,*
FROM
#Test AS T1
CROSS APPLY ListOfDates AS Dated
WHERE
Dated.[Date] >= (SELECT MIN(JobStart) FROM #Test)
AND Dated.[Date] <= (SELECT MAX(JobEnd) FROM #Test)
AND Dated.[Date] >= T1.JobStart AND Dated.[Date] <= T1.JobEnd
)
SELECT DISTINCT Id, Person, Job, JobStart, JobEnd
FROM Thing
WHERE
MY_Rank = 1
CodePudding user response:
Here's an attempt. But it's as far as I'll get with this SQL puzzle.
The idea was to generate a Tally CTE for all dates.
Join the dates to the ranges.
Use row_number to assign the priority job for a date.
Filter priority 1 and generate a ranking.
Group it all up with the ranking.
WITH RCTE_DATES AS (
SELECT MIN(JobStart) AS JobDate, MAX(JobEnd) AS LastDate
FROM #Test
UNION ALL
SELECT DATEADD(day, 1, JobDate), LastDate
FROM RCTE_DATES
WHERE JobDate < LastDate
)
, CTE_RANGES AS
(
SELECT JobDate, Person, Job, JobStart, JobEnd
, ROW_NUMBER() OVER (PARTITION BY Person, JobDate ORDER BY Modified DESC, JobEnd) rn
FROM RCTE_DATES d
JOIN #Test t ON d.JobDate BETWEEN t.JobStart AND t.JobEnd
)
, CTE_RANKED AS
(
SELECT JobDate, Person, Job
, ROW_NUMBER() OVER (PARTITION BY Person, Job ORDER BY JobDate DESC)
ROW_NUMBER() OVER (ORDER BY JobDate) AS Rnk
FROM CTE_RANGES
WHERE rn = 1
GROUP BY JobDate, Person, Job
)
SELECT Person, Job
, MIN(JobDate) AS JobStart
, MAX(JobDate) AS JobEnd
FROM CTE_RANKED
GROUP BY Person, Job, Rnk
ORDER BY JobStart
Person | Job | JobStart | JobEnd
-----: | --: | :--------- | :---------
1 | 6 | 2020-01-01 | 2020-01-02
1 | 2 | 2020-01-03 | 2020-01-09
1 | 1 | 2020-01-10 | 2020-01-20
1 | 5 | 2020-01-21 | 2020-01-25
1 | 6 | 2020-01-26 | 2020-01-30
db<>fiddle here
Side-note: If the lines of the first graph are put on different hights, you can get a different second top view graph. In the sql that can be done by changing the order in CTE_RANGES