I am running this Cronjob at 2 AM in the morning:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: postgres-backup
spec:
# Backup the database every day at 2AM
schedule: "0 2 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: postgres-backup
image: postgres:10.4
command:
- "/bin/sh"
- -c
- |
pg_dump -Fc -d postgresql://$DBUSER:$DBPASS@$DBHOST:$DBPORT/$DBNAME > /var/backups/backup_$(date "%d-%m-%Y_%H-%M").bak;
env:
- name: DBHOST
valueFrom:
configMapKeyRef:
name: dev-db-config
key: db_host
- name: DBPORT
valueFrom:
configMapKeyRef:
name: dev-db-config
key: db_port
- name: DBNAME
valueFrom:
configMapKeyRef:
name: dev-db-config
key: db_name
- name: DBUSER
valueFrom:
secretKeyRef:
name: dev-db-secret
key: db_username
- name: DBPASS
valueFrom:
secretKeyRef:
name: dev-db-secret
key: db_password
volumeMounts:
- mountPath: /var/backups
name: postgres-backup-storage
- name: postgres-restore
image: postgres:10.4
volumeMounts:
- mountPath: /var/backups
name: postgres-backup-storage
restartPolicy: OnFailure
volumes:
- name: postgres-backup-storage
hostPath:
# Ensure the file directory is created.
path: /var/volumes/postgres-backups
type: DirectoryOrCreate
The jobs are getting executed successfully, but what I don't like is that for every Job execution a new Pod is created:
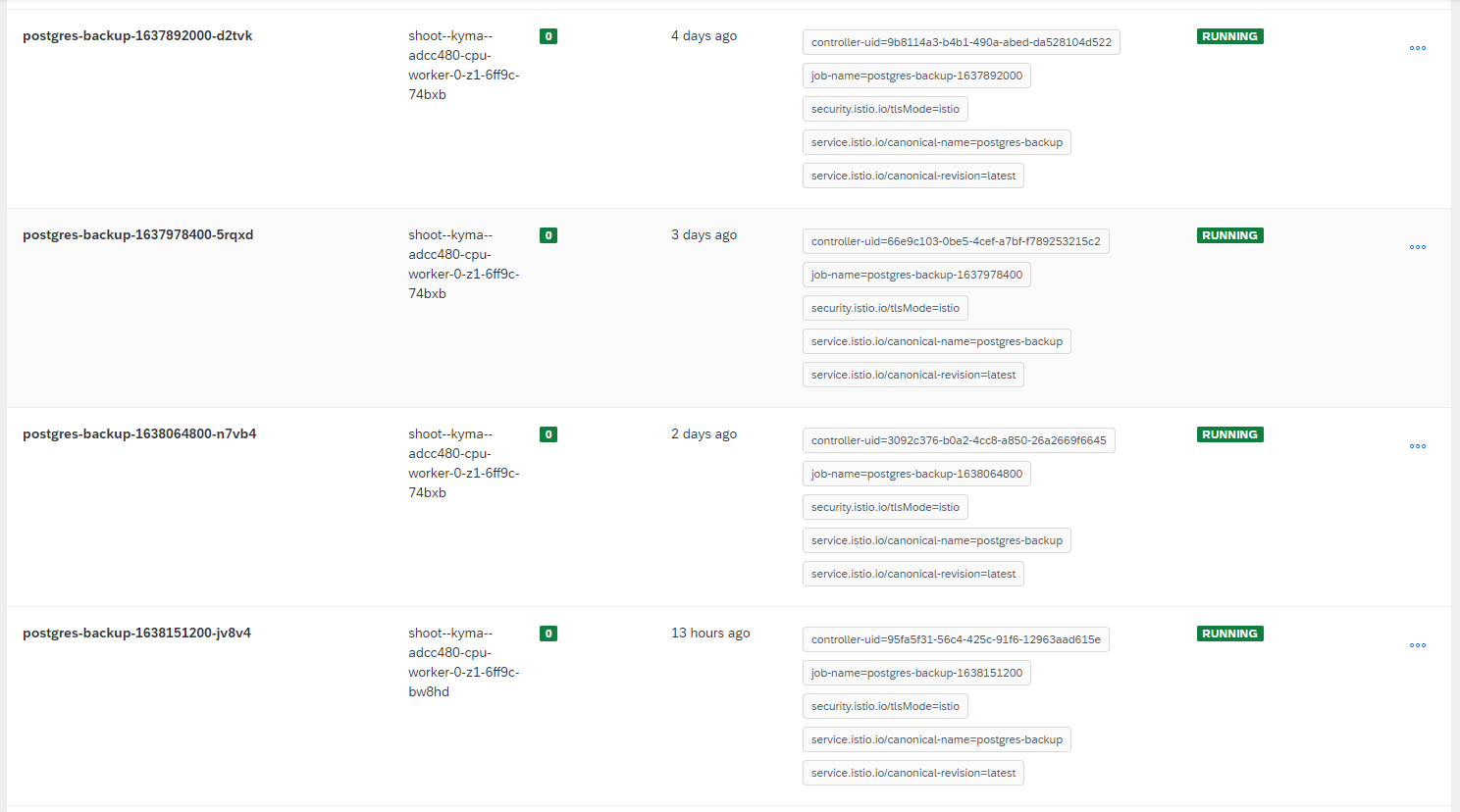
Is there a way to clean previous (old) created Pods? Or maybe is there a way to rerun one an the same Pod/Job every time?
CodePudding user response:
There are two ways to fix this
First method, with the job spec
add a .spec.activeDeadlineSeconds field of the Job to a number of seconds. The activeDeadlineSeconds applies to the duration of the job
Once a Job reaches activeDeadlineSeconds, all of its running Pods are terminated and the Job status will become type: Failed with reason: DeadlineExceeded.
Set the activeDeadlineSeconds to be much longer than the expected running time
Second method, with the pod
make the pod so that it terminates itself when the job is complete. Something like altering the command to
pg_dump -Fc -d postgresql://$DBUSER:$DBPASS@$DBHOST:$DBPORT/$DBNAME > /var/backups/backup_$(date "%d-%m-%Y_%H-%M").bak; exit
CodePudding user response:
You can try to set ttlSecondsAfterFinished, to find out more try:
kubectl explain cronjob.spec.jobTemplate.spec.ttlSecondsAfterFinished --api-version=batch/v1beta1
ttlSecondsAfterFinished limits the lifetime of a Job that has finished execution (either Complete or Failed). If this field is set, ttlSecondsAfterFinished after the Job finishes, it is eligible to be automatically deleted. When the Job is being deleted, its lifecycle guarantees (e.g. finalizers) will be honored. If this field is unset, the Job won't be automatically deleted. If this field is set to zero, the Job becomes eligible to be deleted immediately after it finishes. This field is alpha-level and is only honored by servers that enable the TTLAfterFinished feature.
Shortly, the Job created by CronJob will be deleted after specified seconds.
In your case:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: postgres-backup
spec:
# Backup the database every day at 2AM
schedule: "0 2 * * *"
jobTemplate:
spec:
template:
spec:
ttlSecondsAfterFinished: 60 # after 1 minute the job and the pods will be deleted by kubernetes
...
Please note, that ttlSecondsAfterFinished will be applied iff the job was terminated successfully.