I'm trying to figure out which is best option to choose, my primary requirement is to reduce the IO.
- I have a table with 500M records, where the below mentioned query is choosing the default clustered index scan on the table.
- I tried to create a covering non-clustered index but it still choses the clustered index scan as default. so I have forced it to use the covering index and my observations are the logical reads came down from 3M to 1M but the CPU and duration are increased.
- I'm trying to understand the behavior and what is best here.
Query:
set statistics time, io on;
select
min(CampaignID),
max(CampaignID)
from Campaign
where datecreated < dateadd(day, -90, getutcdate())
go
CREATE NONCLUSTERED INDEX [NCIX]
ON [dbo].[Campaign](DateCreated)
INCLUDE (Campaignid)
go
select
min(CampaignID),
max(CampaignID)
from Campaign with (index = NCIX)
where datecreated < dateadd(day, -90, getutcdate())
set statistics time, io off;
Messages:
(1 row affected)
Table 'Campaign'. Scan count 2, logical reads 3548070, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(8 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 14546 ms, elapsed time = 14723 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 3 ms.
(1 row affected)
Table 'Campaign'. Scan count 1, logical reads 1191017, physical reads 0, page server reads 0, read-ahead reads 19, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(6 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 163953 ms, elapsed time = 164163 ms.
Execution plans:
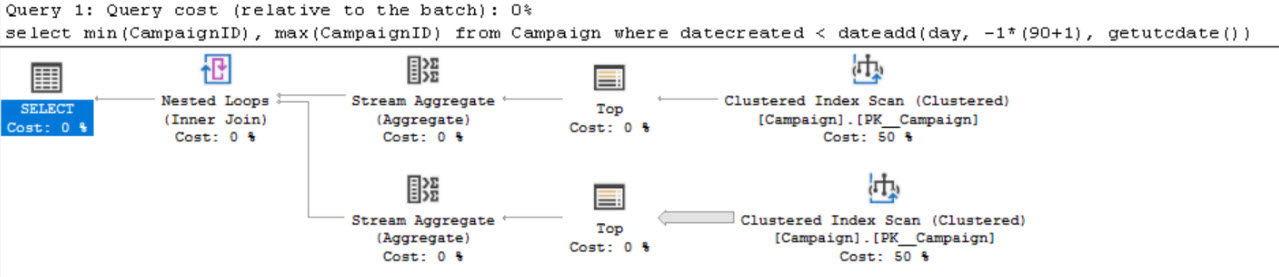

CodePudding user response:
First of all, there is no 'best' operator. Sometimes reading more data is more efficient than reading some data and massage them to get our results. 'Best' as almost everything is relative.
Lets try to understand what happened in the comments...
The query
select
min(CampaignID),
max(CampaignID)
from Campaign
where datecreated < dateadd(day, -90, getutcdate())
Which says:
I want the first and the last ID (min/max) of any record where the date is less than a constant date.
Clustered
The first query without the index/index hint did what SQL Server thought is cheaper than reading any index even if it requires more IO (disk usage). This is because finding the minimum and maximum while validating the records in the table is cheaper than selecting half of the table, then reordering/aggregating them find the exact same info.
The clustered index stores all data on disk and is logically ordered by the key columns, in this case CampaignID (I assume). This means, that to find the minimum and maximum ID is easy: The minimum is the first ID which matches the criteria -> lets check each ID from the first one and stop once we find a record where the date is in place (this will most probably be the first one). The maximum is the first record matching the condition from the end of the index.
Index with the date as key
With the first index (date as the key column), SQL Server can use the date to filter the data, true, but it did not help in sorting. It still has to check every record in that index and figure out the minimum and maximum from a possibly unordered set of values.
Index with the ID as key
With the second index where the ID was the key column, SQL Server can use the same trick as with the clustered key. The only difference is that there is no other data to read, but the ID and the date, which is much smaller than the whole record would be, therefore it can fit in less pages and requires less IO.
SQL Server will most probably choose the second index even if there is no index hint.
Notes
Here I would add a note: optimizing for only one query is not always the best tactic. You can't optimize for everything, if this query runs once a day/week/quarter, that 14-15 seconds runtime with the clustered key will most probably do no harm. If the index does not help other queries, I would not create it, unless it is a mission critical query.