I am looking for a way to query data from Oracle. The idea would be to return values in a given time frame (let's say 2021-01-01 & 2021-12-31). We have a table that stores all changes historically.
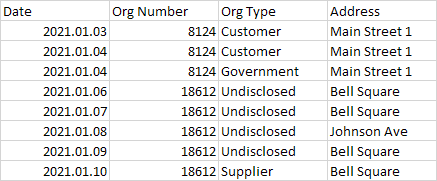
I am only concerned with up to colum 3 (Org Type) and do not care about what changed beside that column.
In essence, I would like to be able to answer: What was Org# 8124's Org Type on 2021.01.04. (in which case it would be the latest since it has changed on that day) Additionally, I since this table only tracks changes, it would need to extend to dates not captured here. Meaning, for example Org# 18612 has last changed on 2021.01.10. so if someone asks, what was its value on 2021.07.07.(which is not captured in the table) it should be the latest.
I managed to get before&after values with LAG, but I am not sure how to work this out, as again, I need to populate everyday with a value (even tho I don't have that date in the table) Not sure if it makes any sense. Any help is appreciated.
CodePudding user response:
lag and similar will not help, because that only works to compare rows that exist in the data already - not some external date you provide. (You can make it work by adding a row to your data, with the input date and null for other columns, using union all, and then use lag - but it shouldn't be lag anyway if your date exists in the data, and in any case it's more complicated than it needs to be.)
Rather, filter the input data by organization id and date, and select the row with the most recent date among those that pass the filter. This last step can be done in many ways (with analytic functions like row_number, with aggregate first/last function, with order by and outer query with filter rownum=1, etc.) Since version 12, it's easiest with fetch ... as shown below, but that only works if you are working over the entire table (or filter by a single organization, etc.) Otherwise the analytic row_number approach is probably best.
So - since I don't have your data - I will use table employees in the standard hr schema to find the most recent row (newest hire_date) on or before 15 December 2006. Instead of "organization id" I filter by department_id, and instead of "organization type" I ask for the then-current job_id.
select department_id, hire_date, job_id
from hr.employees
where department_id = 90
and hire_date <= date '2006-12-15'
fetch first row only
;
DEPARTMENT_ID HIRE_DATE JOB_ID
------------- ----------- ----------
90 17-JUN-2003 AD_PRES
CodePudding user response:
If you store for each change of an entiry a new row with the updat einformation you are basically implementing a SCD of type 2.
To allow more efficient queries with an arbitrary date you may add the (redundant) attribute change_end_d that contains the last day on which this change is valid.
This is either the LEAD date of the next change or for the last change of particular key (org_number) you can use some date in far future or NULL.
Sample Data
ORG_NUMBER CHANGE_D ORG_TYPE ADDRESS
---------- ------------------- --------------- ---------------
8124 03.01.2021 00:00:00 Customer Main Street 1
8124 04.01.2021 00:00:00 Government Main Street 1
18612 06.01.2021 00:00:00 Undisclosed Bell Square
18612 08.01.2021 00:00:00 Undisclosed Johnson Ave
18612 09.01.2021 00:00:00 Undisclosed Bell Square
18612 10.01.2021 00:00:00 Supplier Bell Square
Example
I'm using a view, for large data you may want to use materialized view or a table.
create view v_hist as
select
org_number,
change_d,
lead(change_d,1,DATE'2099-01-01') over (partition by org_number order by change_d) change_end_d,
org_type,
address
from hist;
The view produces this data
ORG_NUMBER CHANGE_D CHANGE_END_D ORG_TYPE ADDRESS
---------- ------------------- ------------------- --------------- ---------------
8124 03.01.2021 00:00:00 04.01.2021 00:00:00 Customer Main Street 1
8124 04.01.2021 00:00:00 01.01.2099 00:00:00 Government Main Street 1
18612 06.01.2021 00:00:00 08.01.2021 00:00:00 Undisclosed Bell Square
18612 08.01.2021 00:00:00 09.01.2021 00:00:00 Undisclosed Johnson Ave
18612 09.01.2021 00:00:00 10.01.2021 00:00:00 Undisclosed Bell Square
18612 10.01.2021 00:00:00 01.01.2099 00:00:00 Supplier Bell Square
Using this view you get the data for 18612 of 2021-07-07 using this query
select * from v_hist
where ORG_NUMBER = 18612 and
DATE'2021-07-07' >= CHANGE_D and DATE'2021-07-07' < CHANGE_END_D;
Some Discussion
The
CHANGE_END_Din the last change (though some would argue is should be null) is typically set to some arbitrary high data as it simplifies the data query.You may even set the
CHANGE_END_Dnot equel to thechange_dof the next version, but a bit lower (1 day in your example, 1 second if the change date contains time). Than the query may be further simplified:
.
select * from v_hist
where ORG_NUMBER = 18612 and
DATE'2021-07-07' BETWEEN CHANGE_D and CHANGE_END_D;
If you have frequent changes it is better to store the exact time or the change to avoid the case of multiple changes with the same date without defined order. See your data row 2 and 3.
Even better is to add a
numbercolumn sayversionthat for each org_number defines the index of the change 1,2,3...