I have a list of strings and a dataframe with a text column. In the text column, I have lines of text. I want to count how many times each word in the list of strings occurs in the text column. I am aiming to add two columns to the dataframe; one column with the word and the other column having the number of occurrences. If there is a better solution, I am open to it. It would be great to learn different ways to accomplish this. I would ideally like one dataframe in the end.
string_list = ['had', 'it', 'the']
Current dataframe:
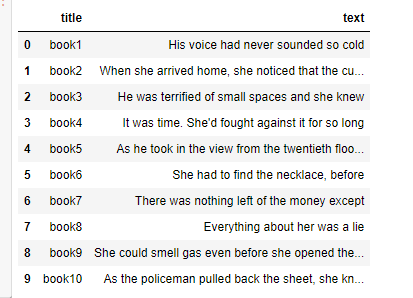
Dataframe in code:
pd.DataFrame({'title': {0: 'book1', 1: 'book2', 2: 'book3', 3: 'book4', 4: 'book5'},
'text': {0: 'His voice had never sounded so cold',
1: 'When she arrived home, she noticed that the curtains were closed.',
2: 'He was terrified of small spaces and she knew',
3: "It was time. She'd fought against it for so long",
4: 'As he took in the view from the twentieth floor, the lights went out all over the city'},
'had': {0: 1, 1: 5, 2: 5, 3: 2, 4: 5},
'it': {0: 1, 1: 3, 2: 2, 3: 1, 4: 2},
'the': {0: 1, 1: 4, 2: 5, 3: 3, 4: 3}})
Attempting to get a dataframe like this:
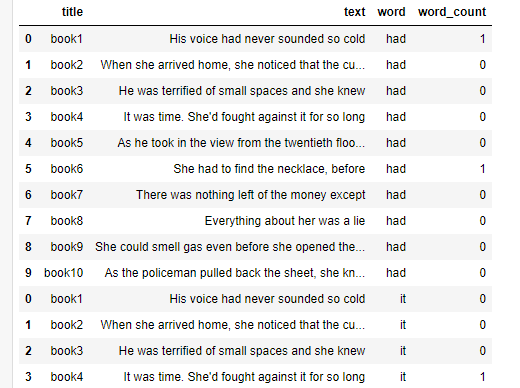
CodePudding user response:
Function to find the number of matches for a given pattern:
def find_match_count(word: str, pattern: str) -> int:
return len(re.findall(pattern, word.lower()))
Then loop through each of the strings, and apply this function to the 'word' column:
for col in string_list:
df[col] = df['text'].apply(find_match_count, pattern=col)
When using the data frame you provided (without the had, it and the columns) gives:
title text had it the
0 book1 His voice had never sounded so cold 1 0 0
1 book2 When she arrived home, she noticed that the cu... 0 0 1
2 book3 He was terrified of small spaces and she knew 0 0 0
3 book4 It was time. She'd fought against it for so long 0 2 0
4 book5 As he took in the view from the twentieth floo... 0 1 4
CodePudding user response:
Define a custom regex, extractall, join, and melt:
regex = '|'.join(fr'(?P<{w}>\b{w}\b)' for w in string_list)
(df[['title', 'text']]
.join(df['text'].str.extractall(regex).notna().groupby(level=0).sum())
.fillna(0)
.melt(id_vars=['title', 'text'], var_name='word', value_name='word count')
)
Output:
title text word word count
0 book1 His voice had never sounded so cold had 1.0
1 book2 When she arrived home, she noticed that the cu... had 0.0
2 book3 He was terrified of small spaces and she knew had 0.0
3 book4 It was time. She'd fought against it for so long had 0.0
4 book5 As he took in the view from the twentieth floo... had 0.0
5 book1 His voice had never sounded so cold it 0.0
6 book2 When she arrived home, she noticed that the cu... it 0.0
7 book3 He was terrified of small spaces and she knew it 0.0
8 book4 It was time. She'd fought against it for so long it 1.0
9 book5 As he took in the view from the twentieth floo... it 0.0
10 book1 His voice had never sounded so cold the 0.0
11 book2 When she arrived home, she noticed that the cu... the 1.0
12 book3 He was terrified of small spaces and she knew the 0.0
13 book4 It was time. She'd fought against it for so long the 0.0
14 book5 As he took in the view from the twentieth floo... the 4.0