Say I have the following SQLite v3 table, which holds some names per each country:
Germany Peter,Jan,David,Florian
USA James,Joe,Bob,David,Alan,George
UK George,Jack,Peter
Israel David,Moshe,Chaim
The names for each country are separated using commas.
I want to count how many unique names there are in total, which in this case will be 12 (since e.g. David is both in Germany, USA and Israel).
Is there a direct way to do it via a SQL query?
CodePudding user response:
Is there a direct way to do it via a SQL query?
I believe that the following will produce the count of unique names directly:-
WITH
splt(value,rest) AS
(
SELECT
substr(names,1,instr(names,',')-1),
substr(names,instr(names,',') 1)||','
FROM thetable
UNION ALL SELECT
substr(rest,1,instr(rest,',')-1),
substr(rest,instr(rest,',') 1)
FROM splt
WHERE length(rest) > 0
LIMIT 20 /* just in case limit to 20 iterations increase if more iterations exected */
),
intermediate AS
(
SELECT count(*),
group_concat(value)
FROM splt
WHERE length(value) > 0
GROUP BY value
)
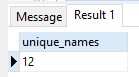
SELECT count(*) AS unique_names FROM intermediate;
Explanation
This assumes that the country is in a column and that the names are in another column and that the column name is names in a table named thetable
The query consists of 2 CTE's (Common Table Expressions which are basically temporary tables).
The first CTE named splt is recursive it extracts each name in the list as a row.
Note that a recursive CTE MUST have some means of determining when to stop iterating a WHERE clause or a LIMIT. In the case both are used the WHERE clause is the correct check ceasing the iterations (on a per source row basis) when the length of the extracted value is greater than 0. The LIMIT 20 is a precautionary measure, of course it may be increased.
The second CTE, named intermediate then removes 0 length names and duplicates by grouping according to value using the result from the splt CTE.
Finally the number of remaining rows is counted.
Demonstration
Using the following to demonstrate:-
DROP TABLE IF EXISTS thetable;
CREATE TABLE IF NOT EXISTS thetable (country TEXT, names TEXT);
INSERT INTO thetable VALUES
('Germany','Peter,Jan,David,Florian'),
('USA','James,Joe,Bob,David,Alan,George'),
('UK','George,Jack,Peter'),
('Isreal','David,Moshe,Chaim'),
/*<<<<< ADDED to test resillience*/
('Spain',''),
('France',null),
('Italy',zeroblob(100))
;
WITH
splt(value,rest) AS
(
SELECT
substr(names,1,instr(names,',')-1),
substr(names,instr(names,',') 1)||','
FROM thetable
UNION ALL SELECT
substr(rest,1,instr(rest,',')-1),
substr(rest,instr(rest,',') 1)
FROM splt
WHERE length(rest) > 0
LIMIT 20 /* just in case limit to 20 iterations increase if more iterations exected */
),
intermediate AS
(
SELECT count(*),
group_concat(value)
FROM splt
WHERE length(value) > 0
GROUP BY value
)
SELECT count(*) AS unique_names FROM intermediate;
DROP TABLE IF EXISTS thetable;
Results in:-